[论文解读] Progressive Prompts: Continual Learning for Language Models
Progressive Prompts 引入一种内存高效的语言模型持续学习方法:对每个任务学习一个新的软提示,并将其与先前的提示逐步拼接,同时保持基础模型冻结,从而实现强前向迁移并且不遗忘。
We introduce Progressive Prompts - a simple and efficient approach for continual learning in language models. Our method allows forward transfer and resists catastrophic forgetting, without relying on data replay or a large number of task-specific parameters. Progressive Prompts learns a new soft prompt for each task and sequentially concatenates it with the previously learned prompts, while keeping the base model frozen. Experiments on standard continual learning benchmarks show that our approach outperforms state-of-the-art methods, with an improvement >20% in average test accuracy over the previous best-preforming method on T5 model. We also explore a more challenging continual learning setup with longer sequences of tasks and show that Progressive Prompts significantly outperforms prior methods.
研究动机与目标
- 通过解决灾难性遗忘和前向迁移,推动语言模型的持续学习。
- 提出一种内存高效的方法,使用任务特定的提示而不进行数据重放或大量参数增长。
- 在 BERT 和 T5 的标准持续学习基准以及更长任务序列上展示其有效性。
- 展示一种提示嵌入重新参数化技术以稳定训练。
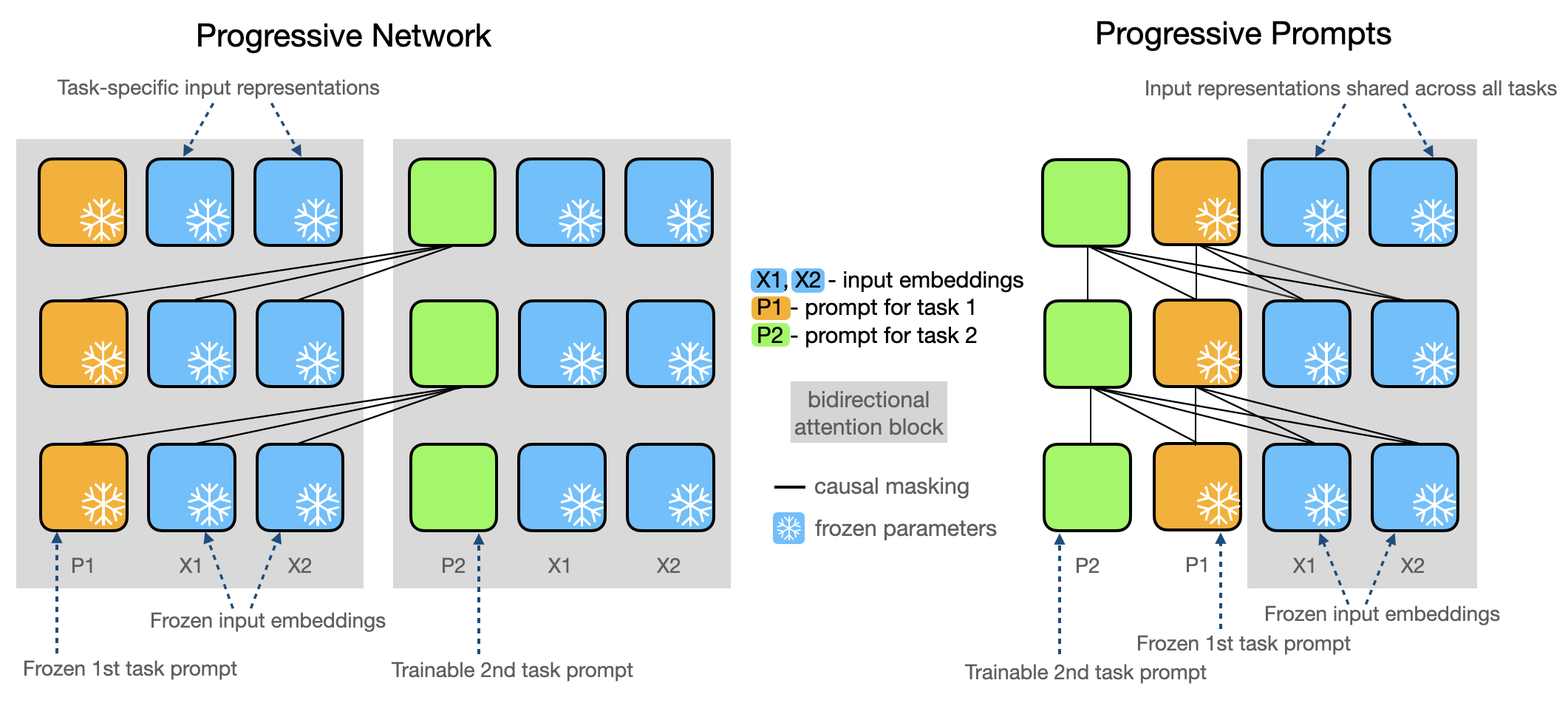
提出的方法
- 为每个到来的任务 T_k 学习一个独立的软提示 P_k。
- 在冻结基础模型的同时,按顺序将新提示与之前学到的所有提示拼接。
- 仅训练任务 T_k 的新提示参数 θ_{P_k}。
- 使用残差多层感知机(MLP)对提示嵌入 P_k 进行重新参数化,使 P_k' = MLP(P_k) + P_k,以稳定训练。
- 训练完成后,丢弃 MLP,但保留投影后的 P_k' 以供将来使用。
- 将该方法应用于 Transformer 模型(BERT 和 T5)并在无数据重放的情况下进行评估。
实验结果
研究问题
- RQ1Progressive Prompts 在一系列任务中能否防止灾难性遗忘?
- RQ2Progressive Prompts 是否能实现前向迁移,在不重新训练基础模型的情况下提升未来任务的学习?
- RQ3提示嵌入重新参数化如何影响语言模型持续学习中的稳定性和性能?
主要发现
- Progressive Prompts 在 BERT 和 T5 的标准文本分类基准上优于最先进的持续学习方法。
- 在 T5 上,在少样本设置中,Progressive Prompts 的平均准确率比先前最佳方法提高超过 20%。
- 在较长任务序列(15 个任务)中,Progressive Prompts 明显优于先前方法,适用于 BERT 和 T5。
- 使用残差 MLP 进行嵌入重新参数化在长期内稳定并提升提示微调性能,同时不增加参数数量。
- 该方法与模型无关,不需要数据重放或存储大量任务特定参数。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。