[论文解读] Propagate Yourself: Exploring Pixel-Level Consistency for Unsupervised Visual Representation Learning
本文提出PixPro,一种新型的无监督视觉表征学习方法,引入像素级的掩码任务——具体为像素到传播一致性(pixel-to-propagation consistency)——以学习空间敏感的密集特征表示。通过鼓励同一像素在标准特征与经过平滑传播后的版本之间保持一致性,PixPro在下游密集预测任务中实现了最先进(SOTA)的迁移性能,在Pascal VOC上比实例级对比学习方法高出2.6 AP,在COCO上高出0.8–1.0 mAP。
Contrastive learning methods for unsupervised visual representation learning have reached remarkable levels of transfer performance. We argue that the power of contrastive learning has yet to be fully unleashed, as current methods are trained only on instance-level pretext tasks, leading to representations that may be sub-optimal for downstream tasks requiring dense pixel predictions. In this paper, we introduce pixel-level pretext tasks for learning dense feature representations. The first task directly applies contrastive learning at the pixel level. We additionally propose a pixel-to-propagation consistency task that produces better results, even surpassing the state-of-the-art approaches by a large margin. Specifically, it achieves 60.2 AP, 41.4 / 40.5 mAP and 77.2 mIoU when transferred to Pascal VOC object detection (C4), COCO object detection (FPN / C4) and Cityscapes semantic segmentation using a ResNet-50 backbone network, which are 2.6 AP, 0.8 / 1.0 mAP and 1.0 mIoU better than the previous best methods built on instance-level contrastive learning. Moreover, the pixel-level pretext tasks are found to be effective for pre-training not only regular backbone networks but also head networks used for dense downstream tasks, and are complementary to instance-level contrastive methods. These results demonstrate the strong potential of defining pretext tasks at the pixel level, and suggest a new path forward in unsupervised visual representation learning. Code is available at \url{https://github.com/zdaxie/PixPro}.
研究动机与目标
- 解决当前实例级对比学习方法的局限性,这些方法生成的表征在目标检测与语义分割等密集预测任务中表现次优。
- 探究在像素级别定义掩码任务是否能产生比图像级别方法更具空间敏感性的表征。
- 开发一种自监督学习框架,不仅对主干网络进行预训练,也对密集预测任务中使用的头部网络进行预训练。
- 研究像素级与实例级掩码任务之间的互补性,以提升下游任务的迁移性能。
- 证明在低数据量场景下,尤其是半监督学习中,像素级预训练的有效性。
提出的方法
- 提出PixContrast,一种像素级对比学习方法,将每个像素视为独立类别,并通过两个随机裁剪中同一像素的特征形成正样本对。
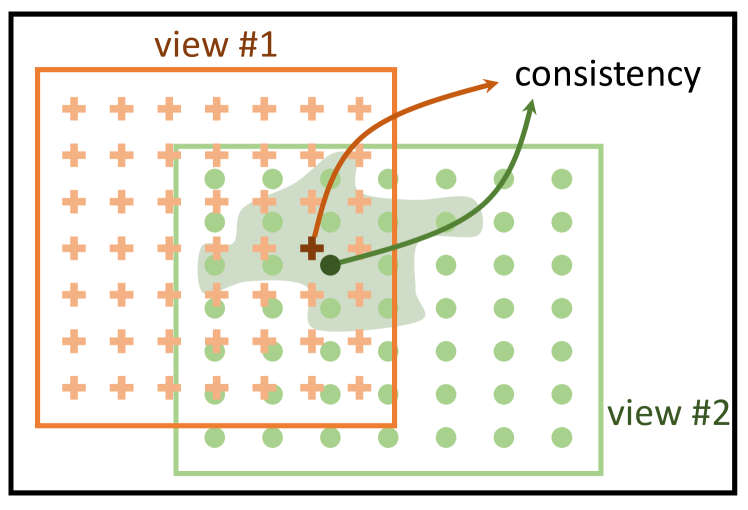
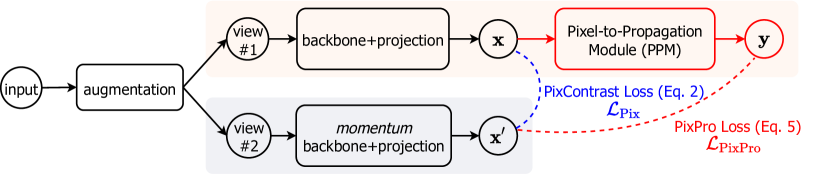
- 引入PixPro,一种像素到传播一致性的方法,采用两个非对称分支:一个使用标准主干网络,另一个使用像素传播模块,通过相似像素对特征进行平滑处理。
- 设计一个传播模块,基于像素间的相似性计算特征权重,过滤并平滑特征,从而与原始特征形成一致的正样本对。
- 使用对比损失进行模型训练,鼓励标准特征与传播后特征之间的一致性,避免显式建模负样本对。
- 将所提出的像素级掩码任务与实例级对比学习(如SimCLR*)结合,以利用其在空间敏感性与分类能力方面的互补优势。
- 使用相同的像素级掩码任务对主干网络和头部网络(如FPN与检测头)进行联合预训练,从而为下游密集预测任务提供更优的初始化。
实验结果
研究问题
- RQ1在像素级别定义掩码任务是否能为目标检测与语义分割等密集预测任务带来更优的表征?
- RQ2与直接的像素级对比学习相比,像素到传播一致性在下游性能与表征质量方面表现如何?
- RQ3像素级掩码任务在多大程度上能提升头部网络(通常在实例级对比学习中不被预训练)的预训练效果?
- RQ4结合像素级与实例级掩码任务是否能带来协同增益,从而提升迁移性能?
- RQ5在标注数据有限的半监督学习设置下,像素级预训练的有效性如何?
主要发现
- 在Pascal VOC目标检测任务中(Faster R-CNN R50-C4),PixPro实现60.2 mAP,优于此前最佳方法2.6 AP。
- 在COCO目标检测任务中,PixPro在FPN设置下达到41.4 mAP,在C4设置下达到40.5 mAP,分别优于此前SOTA方法0.8和1.0 mAP。
- 当与实例级对比学习(如SimCLR*)结合时,该方法在Pascal VOC上实现58.7 mAP,在COCO上实现40.9 mAP,显示出互补性增益。
- 对头部网络(包括FPN与检测头)进行预训练,使FCOS在COCO目标检测任务上提升1.2 mAP,表明端到端预训练的优势。
- 在COCO上使用1%标注数据进行半监督目标检测时,PixPro实现14.8 mAP,较之前无监督方法提升+3.9 mAP。
- 在COCO上使用像素级任务进行额外预训练,可在1%数据下提升+0.7 mAP,在10%数据下提升+0.2 mAP,表明在低数据场景下具有显著优势。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。