[论文解读] ProxylessNAS: Direct Neural Architecture Search on Target Task and\n Hardware
ProxylessNAS 直接在目标任务和目标硬件上学习神经网络结构,降低内存和计算需求,能够实现大规模搜索空间以及硬件感知的定制化,而无需代理任务。
Neural architecture search (NAS) has a great impact by automatically\ndesigning effective neural network architectures. However, the prohibitive\ncomputational demand of conventional NAS algorithms (e.g. $10^4$ GPU hours)\nmakes it difficult to \\emph{directly} search the architectures on large-scale\ntasks (e.g. ImageNet). Differentiable NAS can reduce the cost of GPU hours via\na continuous representation of network architecture but suffers from the high\nGPU memory consumption issue (grow linearly w.r.t. candidate set size). As a\nresult, they need to utilize~\\emph{proxy} tasks, such as training on a smaller\ndataset, or learning with only a few blocks, or training just for a few epochs.\nThese architectures optimized on proxy tasks are not guaranteed to be optimal\non the target task. In this paper, we present \\emph{ProxylessNAS} that can\n\\emph{directly} learn the architectures for large-scale target tasks and target\nhardware platforms. We address the high memory consumption issue of\ndifferentiable NAS and reduce the computational cost (GPU hours and GPU memory)\nto the same level of regular training while still allowing a large candidate\nset. Experiments on CIFAR-10 and ImageNet demonstrate the effectiveness of\ndirectness and specialization. On CIFAR-10, our model achieves 2.08\\% test\nerror with only 5.7M parameters, better than the previous state-of-the-art\narchitecture AmoebaNet-B, while using 6$\\times$ fewer parameters. On ImageNet,\nour model achieves 3.1\\% better top-1 accuracy than MobileNetV2, while being\n1.2$\\times$ faster with measured GPU latency. We also apply ProxylessNAS to\nspecialize neural architectures for hardware with direct hardware metrics (e.g.\nlatency) and provide insights for efficient CNN architecture design.\n
研究动机与目标
- 激励直接在大规模数据集(如 ImageNet)上进行优化、无需代理任务的 NAS。
- 实现不重复块的“大型搜索空间”,并将内存/计算降至常规训练水平。
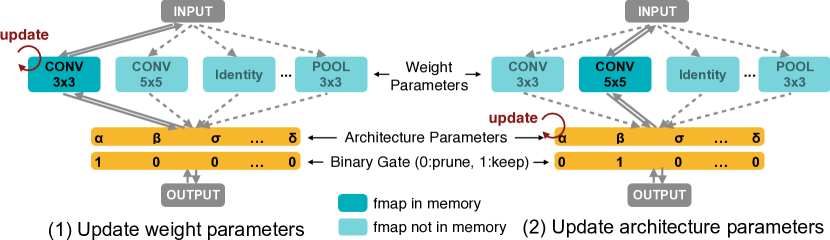
- 引入通过二值化架构参数实现的路径级剪枝,以降低内存使用。
- 通过可微分的延迟建模或基于 REINFORCE 的方法处理不可微的硬件指标(如延迟)。
- 展示针对不同硬件(GPU、CPU、移动端)的架构专用化,具备延迟感知目标。
提出的方法
- 构建一个包含所有候选路径的过参数化网络,作为混合操作。
- 将架构参数二值化,在运行时仅激活一条路径,将内存降至标准训练水平。
- 使用冻结的架构参数训练权重参数,并通过两路径采样,利用梯度估计(受 BinaryConnect 启发)更新架构参数,以保持低内存。
- 将延迟视为可微分的正则项,通过预测各路径延迟并将其期望值乘以延迟权重 λ2 加入损失。
- 当使用不可微延迟目标时,提供基于 REINFORCE 的架构参数更新的替代方案。
- 在 CIFAR-10 和 ImageNet 上进行评估,包括针对移动端、GPU 和 CPU 的硬件感知搜索。

实验结果
研究问题
- RQ1NAS 是否能够直接在大规模任务(如 ImageNet)上优化架构,而无需代理任务?
- RQ2允许学习所有块(不限制重复的 motif)是否能提升性能和效率?
- RQ3在探索大规模基于路径的搜索空间时,内存和计算是否能维持在常规训练水平?
- RQ4将延迟有效地整合为可微分目标以产生硬件感知架构的效果如何?
- RQ5针对 GPU、CPU 和移动设备的硬件专用架构是否存在差异,NAS 能否捕捉这些差异?
主要发现
| 模型 | 参数量 | 测试误差 (%) |
|---|---|---|
| Proxyless-G (ours) + c/o | 5.7M | 2.08 |
| Proxyless-R (ours) + c/o | 5.7M | 2.30 |
- 在 CIFAR-10 上,ProxylessNAS 以 5.7M 参数达到 2.08% 测试误差(超过 AmoebaNet-B,参数大约多出 6×)。
- 在 ImageNet 上,Proxyless-G 达到 75.1% 的 top-1 精度,比 MobileNetV2 延迟快 1.2×,搜索成本比以往方法低 200×。
- Proxyless-G(mobile)在 78 ms 移动端延迟下达到 top-1 74.6%,在相同延迟约束下优于 MobileNetV2。
- Proxyless-NAS 为 GPU、CPU 和移动端找到硬件专用架构,显示出各平台的明显架构偏好(例如:GPU:更浅/更宽;CPU:更深/更窄)。
- 具延迟正则化的延迟感知搜索,比延迟无关的做法在准确性和延迟的折衷上更优。
- 该方法通过路径二值化降低内存,并实现无需重复块的大型架构搜索空间。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。