[论文解读] Pruning vs Quantization: Which is Better?
本文系统比较剪枝和量化在神经网络压缩中的效果,结果是在大多数场景下量化通常优于剪枝,尤其在中等压缩率下;剪枝只有在极高的压缩比时才可能有帮助。
Neural network pruning and quantization techniques are almost as old as neural networks themselves. However, to date only ad-hoc comparisons between the two have been published. In this paper, we set out to answer the question on which is better: neural network quantization or pruning? By answering this question, we hope to inform design decisions made on neural network hardware going forward. We provide an extensive comparison between the two techniques for compressing deep neural networks. First, we give an analytical comparison of expected quantization and pruning error for general data distributions. Then, we provide lower bounds for the per-layer pruning and quantization error in trained networks, and compare these to empirical error after optimization. Finally, we provide an extensive experimental comparison for training 8 large-scale models on 3 tasks. Our results show that in most cases quantization outperforms pruning. Only in some scenarios with very high compression ratio, pruning might be beneficial from an accuracy standpoint.
研究动机与目标
- 推动在模型压缩中进行剪枝与量化的公平比较,避免硬件偏差。
- 开发分析与经验基准,在相同压缩比下比较剪枝和量化的误差。
- 提供逐层和全模型评估,包括理论界限和在真实网络上的实际实验。
提出的方法
- 用对称均匀量化建模量化的权重误差及其均方误差/信噪比(MSE/SNR)行为。
- 将幅值剪枝定义为剪枝方法,并推导其误差与量化中的裁剪相似性。
- 推导一个混合整数二次规划,以计算 PTQ 层输出误差的下界。
- 使用带稀疏掩码的分支定界法为中等维数提供精确的剪枝解。
- 在多种体系结构上,对分布、单层 PTQ 和全模型微调进行广泛实验。
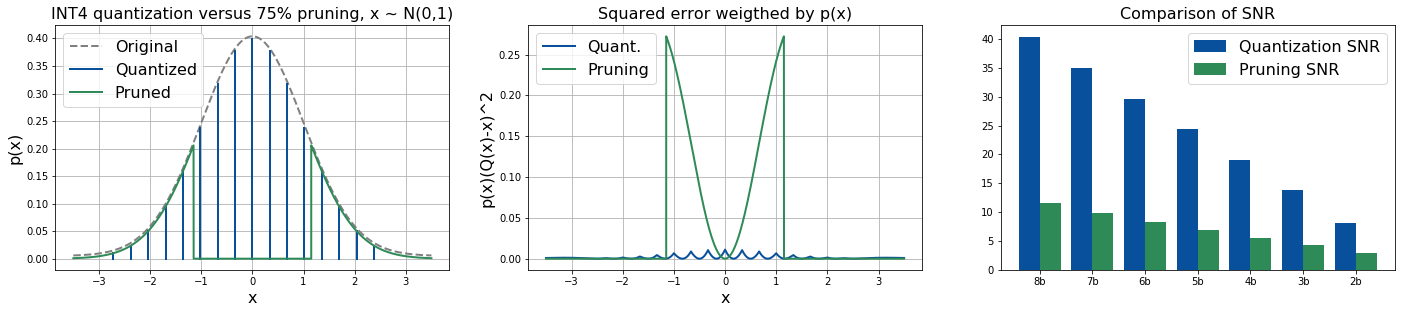
实验结果
研究问题
- RQ1在相同压缩比下,剪枝还是量化能获得更高的输出准确性和更低的误差?
- RQ2数据分布(高斯分布与重尾分布)如何影响剪枝和量化的相对性能?
- RQ3逐层量化和剪枝误差的紧致理论界限是多少,它们与经验结果相比如何?
- RQ4剪枝或量化后的微调是会逆转还是保留学习到的表征,这如何影响性能?
- RQ5从存储和计算角度看,剪枝与量化在实际硬件上的影响是什么?
主要发现
| 模型 | 原始 | 量化 8 位 | 量化 7 位 | 量化 6 位 | 量化 5 位 | 量化 4 位 | 量化 3 位 | 量化 2 位 | 剪枝 8 位 | 剪枝 7 位 | 剪枝 6 位 | 剪枝 5 位 | 剪枝 4 位 | 剪枝 3 位 | 剪枝 2 位 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Resnet-18 | 69.7 | 70.5 | 70.5 | 70.6 | 70.3 | 70.0 | 68.9 | 67.3 | 70.3 | 70.1 | 69.9 | 69.5 | 69.3 | 68.3 | 66.8 |
| Resnet-50 | 76.1 | 76.4 | 76.4 | 76.4 | 76.3 | 76.2 | 75.5 | 72.3 | 76.6 | 76.4 | 76.2 | 76.1 | 75.9 | 75.4 | 74.3 |
| MobileNet-V2 | 71.7 | 71.9 | 72.0 | 71.7 | 71.6 | 70.9 | 68.6 | 59.1 | 68.1 | 65.6 | 61.9 | 56.3 | 48.0 | 34.0 | 21.2 |
| EfficientNet | 75.4 | 75.2 | 75.3 | 75.0 | 74.6 | 74.0 | 71.5 | 60.9 | 72.5 | 70.9 | 68.1 | 63.6 | 56.4 | 44.5 | 27.1 |
| MobileNet-V3 | 67.4 | 67.7 | 67.6 | 67.1 | 66.3 | 64.7 | 60.8 | 50.5 | 65.6 | 64.4 | 62.4 | 60.2 | 56.1 | 31.7 | 0.0 |
| ViT | 81.3 | 81.5 | 81.4 | 81.4 | 81.0 | 80.4 | 78.4 | 72.2 | 76.6 | 76.6 | 76.2 | 73.1 | 72.4 | 71.5 | 69.4 |
| DeepLab-V3 | 72.9 | 72.3 | 72.3 | 72.4 | 71.9 | 70.8 | 63.2 | 17.6 | 65.2 | 62.8 | 56.8 | 47.7 | 32.9 | 18.6 | 10.0 |
| EfficientDet | 40.2 | 39.6 | 39.6 | 39.6 | 39.2 | 37.8 | 33.5 | 15.5 | 34.5 | 33.0 | 30.9 | 27.9 | 24.2 | 17.9 | 8.0 |
- 在中等压缩下,对于权重分布和真实模型张量,量化通常比剪枝产生更高的信噪比(SNR)。
- 只有在极高的压缩(每个值约 2–3 位)和极度稀疏的情况下,剪枝才相对于量化具有优势。
- 在来自 46 个模型的真实模型张量中,权重分布的峰度与剪枝在何时可能优于量化相关;较高的峰度通常有利于量化,除了在极端压缩时。
- 在具有竞争力的 QAT 与剪枝方法的全模型微调中,量化感知训练(QAT)通常在相同压缩率下保持或提高精度,优于幅值剪枝。
- 无结构剪枝给出剪枝性能的上界;硬件因素常会降低剪枝的实际收益,进一步支持量化的论点。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。