[论文解读] Query-Dependent Video Representation for Moment Retrieval and Highlight Detection
论文提出了 QD-DETR,一种将文本查询上下文注入视频表征的查询相关 DETR,用于时刻检索与亮点检测,采用负样本对学习和输入自适应显著性预测器;在 QVHighlights、TVSum、Charades-STA 上达到最先进的 MR/HD 结果。
Recently, video moment retrieval and highlight detection (MR/HD) are being spotlighted as the demand for video understanding is drastically increased. The key objective of MR/HD is to localize the moment and estimate clip-wise accordance level, i.e., saliency score, to the given text query. Although the recent transformer-based models brought some advances, we found that these methods do not fully exploit the information of a given query. For example, the relevance between text query and video contents is sometimes neglected when predicting the moment and its saliency. To tackle this issue, we introduce Query-Dependent DETR (QD-DETR), a detection transformer tailored for MR/HD. As we observe the insignificant role of a given query in transformer architectures, our encoding module starts with cross-attention layers to explicitly inject the context of text query into video representation. Then, to enhance the model's capability of exploiting the query information, we manipulate the video-query pairs to produce irrelevant pairs. Such negative (irrelevant) video-query pairs are trained to yield low saliency scores, which in turn, encourages the model to estimate precise accordance between query-video pairs. Lastly, we present an input-adaptive saliency predictor which adaptively defines the criterion of saliency scores for the given video-query pairs. Our extensive studies verify the importance of building the query-dependent representation for MR/HD. Specifically, QD-DETR outperforms state-of-the-art methods on QVHighlights, TVSum, and Charades-STA datasets. Codes are available at github.com/wjun0830/QD-DETR.
研究动机与目标
- 强调在 MR/HD 任务中真正以查询驱动的视频表示的必要性。
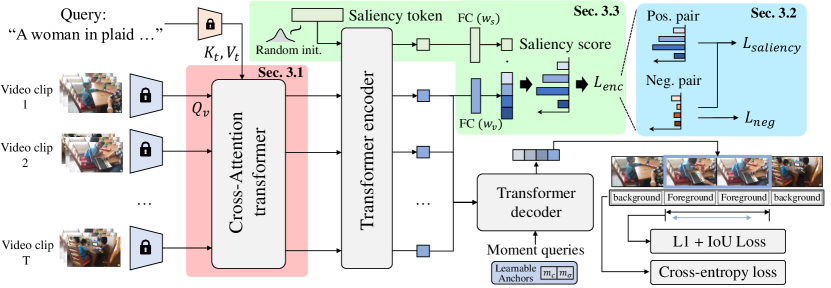
- 开发一个检测-Transformer 基于模型,深度整合文本查询到视频编码中。
- 通过构造并利用负的视频-查询对来促进判别学习。
- 引入一个输入自适应的显著性预测器,以针对不同查询-视频对定制显著性标准。
提出的方法
- 在编码器输入处插入跨注意力,以将视频片段与文本查询特征融合。
- 通过负视频-查询对进行训练,以抑制与查询无关的显著性。
- 使用一个显著性标记作为输入自适应预测器来计算剪辑显著性。
- 实现一个类似 DETR 的解码器,以动态锚点时刻作为查询进行时序定位。
- 用 L1 和广义 IoU 损失来优化 MR,用边界排序和排名感知对比损失来优化 HD。
- 在 MR/HD 基准上联合及单独评估 MR/HD。

实验结果
研究问题
- RQ1查询相关的视频表示是否比查询无关基线在时刻检索和亮点检测上有提升?
- RQ2负视频-查询对学习对显著性估计和时刻定位的影响如何?
- RQ3输入自适应显著性预测器对不同查询的显著性回归有何影响?
- RQ4所提出的组件是否在标准 MR/HD 数据集上实现了最先进的性能?
主要发现
- QD-DETR 在 QVHighlights 上对视频输入仅使用和视频+音频输入时均超越最先进方法。
- 在 QVHighlights 上,QD-DETR with V 在多种指标下达到 62.40 MR mAP;HIT@1 为 62.40 mAP;使用 V+A 时达到 63.06 MR mR 和 62.87 HIT@1 的各变体。
- 在 TVSum 与 Charades-STA 上,QD-DETR 相对于基线显示出显著改进,在多种特征骨干上获得更高的 RS 指标。
- 消融研究表明,跨注意编码、负样本对学习和自适应显著性预测器对 MR/HD 性能贡献显著,甚至超过更深层的自注意力。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。