[论文解读] RA-DIT: Retrieval-Augmented Dual Instruction Tuning
RA-DIT 将任何预训练的大型语言模型通过两阶段微调的检索能力改造(LM 微调以使用检索信息,检索器微调以返回相关结果),在知识密集型任务上达到最前沿的结果,尤其在零-shot 和少-shot 设置中。
Retrieval-augmented language models (RALMs) improve performance by accessing long-tail and up-to-date knowledge from external data stores, but are challenging to build. Existing approaches require either expensive retrieval-specific modifications to LM pre-training or use post-hoc integration of the data store that leads to suboptimal performance. We introduce Retrieval-Augmented Dual Instruction Tuning (RA-DIT), a lightweight fine-tuning methodology that provides a third option by retrofitting any LLM with retrieval capabilities. Our approach operates in two distinct fine-tuning steps: (1) one updates a pre-trained LM to better use retrieved information, while (2) the other updates the retriever to return more relevant results, as preferred by the LM. By fine-tuning over tasks that require both knowledge utilization and contextual awareness, we demonstrate that each stage yields significant performance improvements, and using both leads to additional gains. Our best model, RA-DIT 65B, achieves state-of-the-art performance across a range of knowledge-intensive zero- and few-shot learning benchmarks, significantly outperforming existing in-context RALM approaches by up to +8.9% in 0-shot setting and +1.4% in 5-shot setting on average.
研究动机与目标
- 推动在不进行完全再训练或预训练的情况下提升 LLM 的知识利用率和上下文感知。
- 提出一种轻量级的两步微调方案,将检索能力回装回任何预训练的 LLM 和检索器。
- 证明联合 LM-ft 与 R-ft 在知识密集任务上具有叠加收益。
- 展示 RA-DIT 65B 在零-shot 与少-shot 基准测试上的最新性能。
提出的方法
- 以预训练的 LLaMA 模型为骨干,Dragon+ 作为密集检索器。
- 为每个提示检索 top-k 文本块,并将它们作为 Background 字段并置于指令前,以实现跨块的并行集成。
- LM 微调 (LM-ft): 在增加背景 c i 与指令 x 的条件下,训练 LLM 以最大化 p(y|c i ∘ x),引导模型利用检索到的背景并忽略误导性内容。
- 检索器微调 (R-ft): 训练查询编码器,使检索分数 pR(c|x) 与基于 LM 概似 pLM(y|c∘x) 学得的 LM-监督检索分布 pLSR(c|x,y) 之间的 KL 发散最小化。
- 结合 LM-ft 与 R-ft 以实现联合收益,并在微调过程中未见到的知识密集任务上进行评估。

实验结果
研究问题
- RQ1轻量级的双阶段微调是否能够在不进行完整预训练的情况下,将检索能力回装到现有 LLM?
- RQ2独立的 LM-ft 与 R-ft 阶段是否产生叠加收益,并在结合时如何交互?
- RQ3与现成的 LLM+检索器方法及持续预训练的 RALMs 相比,RA-DIT 在零-shot 与少-shot 知识密集基准上的表现如何?
主要发现
- RA-DIT 65B 在零-shot 与少-shot 知识密集基准上取得最新的结果,在平均跨越 MMLU、NQ、TQA 和 ELI5 的 0-shot(+ 最高 8.9 个百分点)和 5-shot(+ 最高 1.4 个点)设置中,显著优于上下文内置 RALMs。
- RA-DIT 在 8 项任务中的 6 项上超过 Atlas(64-shot 微调的编码器-解码器 RALM),在统一的 64-shot 设置中平均领先 4.1 点。
- LM-ft 与 R-ft 都有贡献;最佳结果来自两者的结合(RA-DIT 相较 RePlug 在 5-shot 平均领先约 0.8 点)。
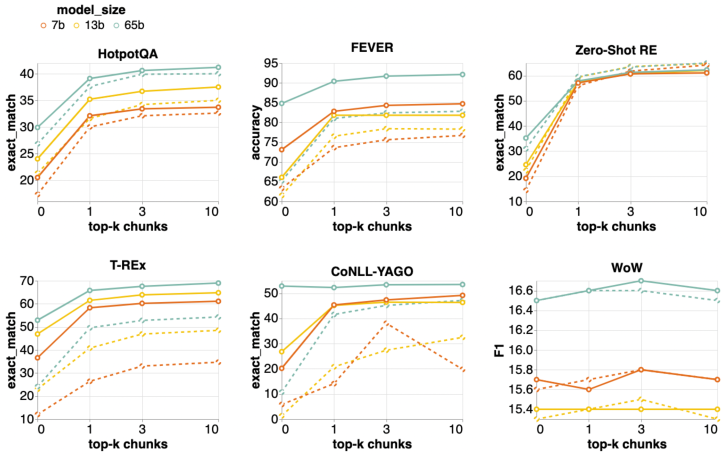
- 检索增强在参数为 65B 的 LLaMA 上即使检索仅限于单个 top-1 块也能提升,使用更多块时可获得进一步增益。
- 使用语料库数据对检索器进行微调通常比仅使用 MTI 数据具有更好的泛化性,在微调查询编码器的同时冻结文档编码器可获得强结果。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。