[论文解读] RAB: Provable Robustness Against Backdoor Attacks
本文提出 RAB,一种可证实鲁棒性的训练框架,针对后门(中毒)攻击,使用对训练数据的随机平滑,具备理论保证和高效实现,并附有大量基准测试。
Recent studies have shown that deep neural networks (DNNs) are vulnerable to adversarial attacks, including evasion and backdoor (poisoning) attacks. On the defense side, there have been intensive efforts on improving both empirical and provable robustness against evasion attacks; however, the provable robustness against backdoor attacks still remains largely unexplored. In this paper, we focus on certifying the machine learning model robustness against general threat models, especially backdoor attacks. We first provide a unified framework via randomized smoothing techniques and show how it can be instantiated to certify the robustness against both evasion and backdoor attacks. We then propose the first robust training process, RAB, to smooth the trained model and certify its robustness against backdoor attacks. We prove the robustness bound for machine learning models trained with RAB and prove that our robustness bound is tight. In addition, we theoretically show that it is possible to train the robust smoothed models efficiently for simple models such as K-nearest neighbor classifiers, and we propose an exact smooth-training algorithm that eliminates the need to sample from a noise distribution for such models. Empirically, we conduct comprehensive experiments for different machine learning (ML) models such as DNNs, support vector machines, and K-NN models on MNIST, CIFAR-10, and ImageNette datasets and provide the first benchmark for certified robustness against backdoor attacks. In addition, we evaluate K-NN models on a spambase tabular dataset to demonstrate the advantages of the proposed exact algorithm. Both the theoretic analysis and the comprehensive evaluation on diverse ML models and datasets shed light on further robust learning strategies against general training time attacks.
研究动机与目标
- 解决缺乏对后门攻击的可证明鲁棒性的问题。
- 开发一个统一框架,将随机平滑扩展到训练时攻击。
- 提出 RAB,一种可证实对后门鲁棒性的鲁棒训练流程。
- 给出理论界限并证明这些界限的紧性。
- 在多种模型和数据集上进行基准测试,以建立基础的鲁棒性基准。
提出的方法
- 定义一个对测试输入和训练数据都进行随机化的平滑分类器。
- 使用 Neyman–Pearson 引理推导一般且紧的鲁棒性条件(定理 1)。
- 用高斯平滑和均匀平滑对框架进行实例化,以证明后门鲁棒性(GaussianCorollary 1)。
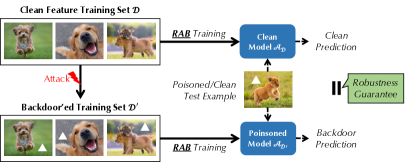
- 提出 RAB 训练:生成 N 个平滑后的训练集,训练 N 个模型,并聚合输出。
- 证明鲁棒性界限是紧的(定理 2)。
- 为 K 最近邻开发一个精确、高效平滑算法(无需蒙特卡罗采样)。
实验结果
研究问题
- RQ1我们能否对 ML 模型在后门(投毒)攻击下的鲁棒性进行证明吗?
- RQ2如何选择平滑分布以证明后门鲁棒性以及由此产生的范数/界限是什么?
- RQ3鲁棒性界限是否紧,在哪些条件下?
- RQ4如何高效地对特定模型族如 K-NN 进行鲁棒性认证?
- RQ5在真实数据集上,DNN、SVM 和 K-NN 的可证鲁棒性界限如何成立?
主要发现
- 首个针对通用 ML 模型对抗后门攻击的可证鲁棒性界限。
- 鲁棒性界限是紧的(定理 2)。
- 给出面向 K-NN 模型的精确高效平滑算法,避免采样。
- 大量实验在 DNN、SVM 和 K-NN 上展示了在 MNIST、CIFAR-10、ImageNette 等数据集上的鲁棒性界限,确立了经过认证的后门鲁棒性基准。
- Spambase 实验说明了精确的 K-NN 平滑算法的优势。
- 代码与评估协议公开发布,以实现可重复的研究。
![Figure 2 : An illustration of the RAB robust training process. Given a poisoned training set $\mathcal{D}+\Delta$ and a training process $\mathcal{A}$ vulnerable to backdoor attacks, RAB generates $N$ smoothed training sets $\{\mathcal{D}_{i}\}_{i\in[N]}$ and trains $N$ different classifiers $\mathc](https://ar5iv.labs.arxiv.org/html/2003.08904/assets/x2.png)
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。