[论文解读] RAG based Question-Answering for Contextual Response Prediction System
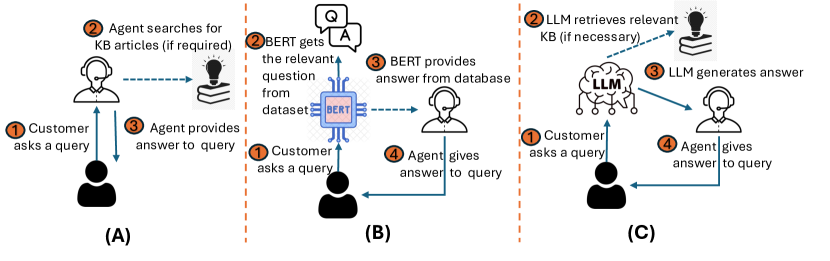
该论文提出一个端到端的检索增强生成(RAG)框架,用于零售客户联系中心的知识基础回应预测系统,与基于BERT的系统相比,提升了准确性并减少了幻觉。
Large Language Models (LLMs) have shown versatility in various Natural Language Processing (NLP) tasks, including their potential as effective question-answering systems. However, to provide precise and relevant information in response to specific customer queries in industry settings, LLMs require access to a comprehensive knowledge base to avoid hallucinations. Retrieval Augmented Generation (RAG) emerges as a promising technique to address this challenge. Yet, developing an accurate question-answering framework for real-world applications using RAG entails several challenges: 1) data availability issues, 2) evaluating the quality of generated content, and 3) the costly nature of human evaluation. In this paper, we introduce an end-to-end framework that employs LLMs with RAG capabilities for industry use cases. Given a customer query, the proposed system retrieves relevant knowledge documents and leverages them, along with previous chat history, to generate response suggestions for customer service agents in the contact centers of a major retail company. Through comprehensive automated and human evaluations, we show that this solution outperforms the current BERT-based algorithms in accuracy and relevance. Our findings suggest that RAG-based LLMs can be an excellent support to human customer service representatives by lightening their workload.
研究动机与目标
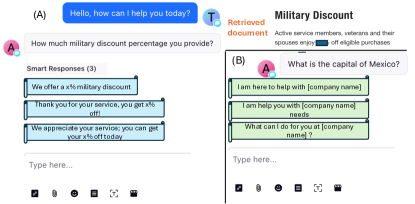
- 在客户服务的行业场景中演示一个可投入生产的RAG框架。
- 识别用于准确、可核验响应的最佳嵌入、检索和提示配置。
- 使用人工和自动化指标对比评估RAG与现有基于BERT的系统。
- 评估ReAct和提示技术在实时环境中的可行性与延迟。
提出的方法
- 构建一个领域特定数据集,包含KB文章、领域内问答和领域外问答。
- 系统性评估嵌入策略(USE、Vertex AI、SBERT)和检索方法(ScaNN、KNN HNSW)。
- 使用PaLM2生成器进行响应生成,并用检索到的KB文章对输出进行校验。
- 调整检索阈值以过滤不必要的检索并优化效率。
- 采用自动化指标和人工评估来评估性能,包括AlignScore和语义相似度。
- 部署生产端点并与代理UI集成以实现实时建议。
实验结果
研究问题
- RQ1RQ1:在该领域中,嵌入技术、检索策略和提示方法如何影响RAG的性能?
- RQ2RQ2:基于RAG的响应是否在帮助人工代理方面优于现有的基于BERT的系统?
- RQ3RQ3:ReAct提示能否在实时环境中提升事实准确性并减少幻觉?
主要发现
| 嵌入 | R@1 | R@3 | R@5 |
|---|---|---|---|
| USE | - | - | - |
| SBERT | +15.36 | +9.42 | +8.22 |
| Vertex AI | +21.55 | +13.87 | +11.85 |
- 本数据中,Vertex AI嵌入与ScaNN检索在Recall@K方面优于其他嵌入。
- 检索阈值约为0.7时能够有效区分何时需要检索,从而提高效率。
- 相对于基于BERT的系统,RAG生成的回答在自动评估中将准确性提高了10.15%,幻觉减少了4.76%。
- 人工评估者在75%的情形下更偏好RAG生成的回答。
- 与BERT基系统相比,RAG在AlignScore平均提高5.6%,语义相似度提高20%。
- ReAct和链式提示在延迟可接受性方面收益有限;在本场景中,像CoVe/CoTP这样的提示技术未带来收益。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。