[论文解读] RAGBench: Explainable Benchmark for Retrieval-Augmented Generation Systems
RAGBench 引入一个大规模、100k-sample 的检索增强生成(RAG)基准,以及一个 TRACe 评估框架(Utilization、Relevance、Adherence、Completeness),并提供 ground-truth 注释以在多个领域评估 RAG 系统。
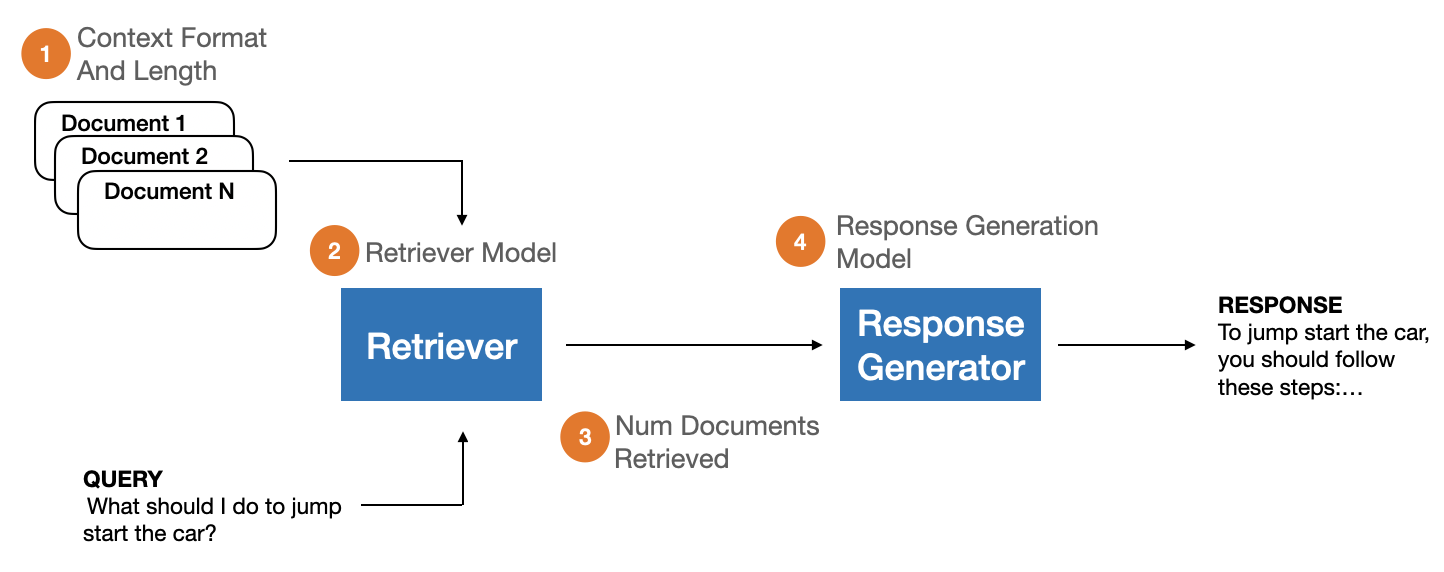
Retrieval-Augmented Generation (RAG) has become a standard architectural pattern for incorporating domain-specific knowledge into user-facing chat applications powered by Large Language Models (LLMs). RAG systems are characterized by (1) a document retriever that queries a domain-specific corpus for context information relevant to an input query, and (2) an LLM that generates a response based on the provided query and context. However, comprehensive evaluation of RAG systems remains a challenge due to the lack of unified evaluation criteria and annotated datasets. In response, we introduce RAGBench: the first comprehensive, large-scale RAG benchmark dataset of 100k examples. It covers five unique industry-specific domains and various RAG task types. RAGBench examples are sourced from industry corpora such as user manuals, making it particularly relevant for industry applications. Further, we formalize the TRACe evaluation framework: a set of explainable and actionable RAG evaluation metrics applicable across all RAG domains. We release the labeled dataset at https://huggingface.co/datasets/rungalileo/ragbench. RAGBench explainable labels facilitate holistic evaluation of RAG systems, enabling actionable feedback for continuous improvement of production applications. Thorough extensive benchmarking, we find that LLM-based RAG evaluation methods struggle to compete with a finetuned RoBERTa model on the RAG evaluation task. We identify areas where existing approaches fall short and propose the adoption of RAGBench with TRACe towards advancing the state of RAG evaluation systems.
研究动机与目标
- 在多领域推动对检索增强生成(RAG)系统的标准化评估。
- 提供覆盖多个行业的大规模真实场景 RAG 基准(100k 样本)。
- 定义 TRACe 框架以量化检索器与生成器组件对 RAG 质量的贡献。
- 通过细粒度且可解释的标签,使系统改进具有可操作的反馈。
提出的方法
- 汇聚来自 12 个来源的组件数据集,涵盖生物医学、通用知识、法律、客户支持和金融等领域,统一为 RAG 格式。
- 改变 RAG 参数:上下文长度、检索文档数量、领域和生成模型,以模拟生产环境。
- 使用 GPT-4-turbo 提示并结合链式推理技术,对 ground-truth 的相关性、利用率和遵循标记进行注释;从 spans 推导 Completeness。
- 提出 TRACe 指标:Context Relevance、Context Utilization、Completeness 和 Adherence,基于 token spans 的形式定义。
- 在 RAGBench 上评估现有的 RAG 评估方法(LLM judges、RAGAS、TruLens)以及一个经过微调的基于 DeBERTa 的评估器。
- 提供基准比较,显示 LLM judge 在 TRACe 指标上常常不及经过微调的专家模型。
实验结果
研究问题
- RQ1大规模、跨域的 RAG 基准是否能够实现对检索器与生成器组件的一致性评估?
- RQ2可解释的 TRACe 指标(Utilization、Relevance、Adherence、Completeness)是否能为改进生产中的 RAG 系统提供可执行的指导?
- RQ3在跨域的 RAG 评估中,零-shot/少-shot 的 LLM 判定与微调的判别模型相比如何?
- RQ4在 RAGBench 中,预测 context relevance 与 utilization 的相对难度如何?
- RQ5在大多数数据集上,微调一个较小的模型(如 DeBERTa-large)是否优于基于 LLM 的评估器?
主要发现
| 数据集 | Hal_GPT3.5 | Rel_GPT3.5 | Util_GPT3.5 | Hal_RAGAS | Rel_RAGAS | Util_RAGAS | Hal_TruLens | Rel_TruLens | Util_TruLens | Hal_DeBERTA | Rel_DeBERTA | Util_DeBERTA |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PubMedQA | 0.51 | 0.21 | 0.16 | 0.54 | 0.37 | - | 0.62 | 0.45 | - | 0.80 | 0.26 | 0.17 |
| CovidQA-RAG | 0.57 | 0.18 | 0.11 | 0.58 | 0.17 | - | 0.62 | 0.58 | - | 0.77 | 0.19 | 0.11 |
| HotpotQA | 0.59 | 0.11 | 0.08 | 0.62 | 0.14 | - | 0.64 | 0.73 | - | 0.85 | 0.11 | 0.08 |
| MS Marco | 0.65 | 0.23 | 0.11 | 0.63 | 0.25 | - | 0.62 | 0.61 | - | 0.70 | 0.22 | 0.10 |
| HAGRID | 0.58 | 0.22 | 0.15 | 0.62 | 0.22 | - | 0.67 | 0.69 | - | 0.81 | 0.20 | 0.13 |
| ExpertQA | 0.55 | 0.31 | 0.23 | 0.57 | 0.28 | - | 0.70 | 0.60 | - | 0.87 | 0.18 | 0.11 |
| DelucionQA | 0.57 | 0.18 | 0.10 | 0.70 | 0.22 | - | 0.55 | 0.64 | - | 0.64 | 0.15 | 0.10 |
| EManual | 0.54 | 0.17 | 0.11 | 0.57 | 0.27 | - | 0.61 | 0.64 | - | 0.76 | 0.13 | 0.13 |
| TechQA | 0.51 | 0.10 | 0.05 | 0.52 | 0.12 | - | 0.57 | 0.70 | - | 0.86 | 0.08 | 0.04 |
| FinQA | 0.57 | 0.10 | 0.13 | 0.57 | 0.06 | - | 0.53 | 0.79 | - | 0.81 | 0.10 | 0.10 |
| TAT-QA | 0.52 | 0.20 | 0.17 | 0.63 | 0.18 | - | 0.59 | 0.72 | - | 0.83 | 0.27 | 0.23 |
| CUAD | 0.51 | 0.27 | 0.11 | 0.66 | 0.19 | - | 0.40 | 0.66 | - | 0.80 | 0.24 | 0.10 |
- RAGBench 覆盖五个领域、12 个组件数据集,总计 100k样本,其中包括长上下文的 CUAD 和数值密集的 FinQA/TAT-QA。
- TRACe 指标实现对检索器相关性、上下文利用、遵循性和生成答案的完整性等方面的细粒度评估。
- 在大多数数据集上,经过微调的 DeBERTa-large 通常优于零-shot 的 LLM 判定在 TRACe 指标上的表现。
- 上下文相关性比利用率更难预测(RMSE 更高),这反映了识别正确答案所需上下文的复杂性。
- LLM 判定(GPT-3.5、RAGAS、TruLens)在与经过微调的专家模型相比时表现具竞争力但并非普遍优越。
- 通过 GPT-4-turbo 的 RAGBench 注释在模拟数据上与真实值达到较高的 Kendall’s τ 相关性,支持注释的有效性。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。