[论文解读] Ray: A Distributed Framework for Emerging AI Applications
Ray 将训练、仿真与服务整合到强化学习工作负载中,采用动态任务/演员模型以及可扩展、容错的执行引擎;它的吞吐量可达每秒数百万个任务,并在 RL 任务上优于专用系统。
The next generation of AI applications will continuously interact with the environment and learn from these interactions. These applications impose new and demanding systems requirements, both in terms of performance and flexibility. In this paper, we consider these requirements and present Ray---a distributed system to address them. Ray implements a unified interface that can express both task-parallel and actor-based computations, supported by a single dynamic execution engine. To meet the performance requirements, Ray employs a distributed scheduler and a distributed and fault-tolerant store to manage the system's control state. In our experiments, we demonstrate scaling beyond 1.8 million tasks per second and better performance than existing specialized systems for several challenging reinforcement learning applications.
研究动机与目标
- 在动态环境中,说明需要一个统一框架来处理 RL 工作负载(训练、仿真、服务).
- 提出一个支持任务并行和基于演员的计算的单一动态执行引擎。
- 设计一个具有分布式调度器和元数据存储的可扩展、容错系统,用于管理控制状态和血统跟踪。
提出的方法
- 引入统一的任务 API(无状态远程函数)和 actors(有状态对象)。
- 实现一个动态任务图执行模型,在输入可用时自动触发计算。
- 使用 Global Control Store、自下而上的分布式调度器,以及 in-memory object store 构建 Ray,以实现低延迟和可扩展性。
- 通过分片元数据和血统跟踪来将控制状态与计算解耦,以实现容错。
- 支持嵌套远程函数和资源感知调度,以处理异构工作负载。
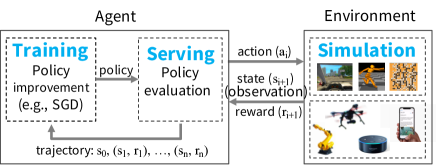
实验结果
研究问题
- RQ1单一框架如何高效支持需要仿真、分布式训练和策略服务的 RL 工作负载?
- RQ2哪些架构选择能够在动态、异构任务中实现毫秒级延迟、高吞吐量和容错性?
- RQ3统一的 actor/任务模型是否能够在 RL 应用中超越拼接的多系统方法?
主要发现
- 在实验中,Ray 的扩展超过每秒 1.8 million 个任务。
- Ray 实现毫秒级延迟,结合 bottom-up distributed scheduler 和分片元数据存储。
- Global Control Store 使无状态组件成为可能,并实现可扩展的容错血统跟踪。
- Ray 提供就地性任务放置和在大型集群上的近线性可扩展性。
- Ray 在若干 RL 应用(训练、服务、仿真)上展现出优于现有专用系统的性能。
- 对象存储实现高吞吐量,写入吞吐量超过 15 GB/s,并在同一节点上实现零拷贝数据共享。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。