[论文解读] Real-Time Detection and Analysis of Vehicles and Pedestrians using Deep Learning
本论文比较 YOLOv8 和 RT-DETR 在城市数据上的实时车辆与行人检测,发现 YOLOv8m 作为基线中最强,经过增强后 YOLOv8l 表现最佳,RT-DETR 变体也具有竞争力。
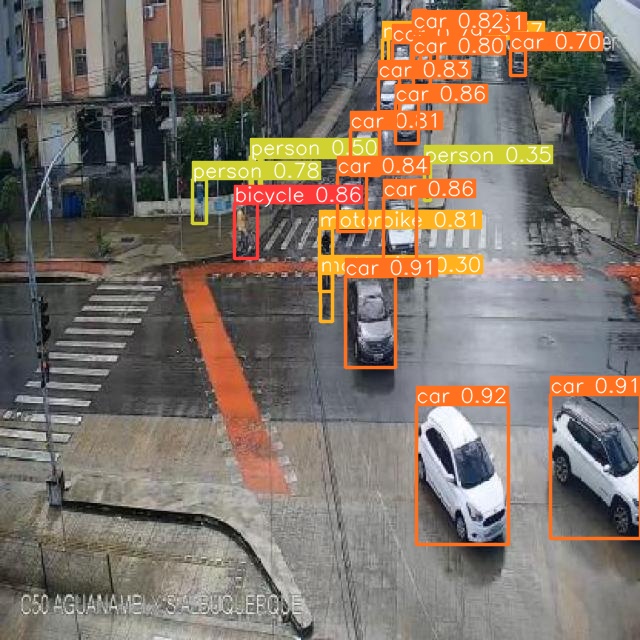
Computer vision, particularly vehicle and pedestrian identification is critical to the evolution of autonomous driving, artificial intelligence, and video surveillance. Current traffic monitoring systems confront major difficulty in recognizing small objects and pedestrians effectively in real-time, posing a serious risk to public safety and contributing to traffic inefficiency. Recognizing these difficulties, our project focuses on the creation and validation of an advanced deep-learning framework capable of processing complex visual input for precise, real-time recognition of cars and people in a variety of environmental situations. On a dataset representing complicated urban settings, we trained and evaluated different versions of the YOLOv8 and RT-DETR models. The YOLOv8 Large version proved to be the most effective, especially in pedestrian recognition, with great precision and robustness. The results, which include Mean Average Precision and recall rates, demonstrate the model's ability to dramatically improve traffic monitoring and safety. This study makes an important addition to real-time, reliable detection in computer vision, establishing new benchmarks for traffic management systems.
研究动机与目标
- 开发一个快速、准确的深度学习框架,用于在多样化城市环境中的实时车辆与行人检测。
- 在交通数据上评估单阶段检测器(YOLOv8 变体)和基于变换器的检测器(RT-DETR)。
- 在基线和增强数据集上评估性能并考察行人聚焦结果。
提出的方法
- 从公开交通视频中进行帧采样,创建包含六个类别的1,142张图像、3,388个注释的数据集。
- 包括色调、曝光、噪声、错切、饱和度和模糊的数据增强,将数据集扩展到3,082张图像。
- 在基线和增强数据集上比较 YOLOv8(s, m, l, x)和 RT-DETR(L, x)模型。
- 训练:批量大小8,图像640x640,最多100个 epoch,在 NVIDIA Tesla P1000 上进行;使用 mAP、精度和召回率进行评估。

实验结果
研究问题
- RQ1哪种模型(YOLOv8 与 RT-DETR)在实时车辆与行人检测中在准确性和速度之间提供最佳权衡?
- RQ2数据增强如何影响跨模型和类别(车辆与行人)的检测性能?
- RQ3在基线和增强条件下,各类别的检测能力如何,行人检测与车辆检测有何差异?
主要发现
| Model | mAP | Precision | Recall |
|---|---|---|---|
| YOLOv8s | 0.798 | 0.814 | 0.764 |
| YOLOv8m | 0.898 | 0.861 | 0.867 |
| YOLOv8l | 0.898 | 0.877 | 0.835 |
| YOLOv8x | 0.818 | 0.895 | 0.735 |
| RT-DETR-L | 0.867 | 0.871 | 0.832 |
| RT-DETR-x | 0.878 | 0.886 | 0.850 |
- YOLOv8m 在基线下达到最高的 mAP 0.898,精度为 0.861,召回为 0.867。
- RT-DETR-x 在基线数据上显示出有竞争力的 mAP(0.878)以及较强的精度(0.886)和召回(0.850)。
- 在增强数据上,YOLOv8l 达到最高的 mAP 0.909,精度为 0.884,召回为 0.861。
- 增强数据下的行人检测:YOLOv8l 的 mAP 为 0.822,精度为 0.909,召回为 0.687(随模型不同而异)。
- 测试时推断:YOLOv8 模型在 40 FPS;RT-DETR 在 25 FPS,表明适用于实时交通监控。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。