[论文解读] RealmDreamer: Text-Driven 3D Scene Generation with Inpainting and Depth Diffusion
RealmDreamer 从文本生成面向前方的 3D 场景,通过使用一个 3D Gaussian Splatting 模型,结合 2D diffusion priors、修补(Inpainting)和 depth diffusion 进行初始化,在没有多视图数据的情况下产生高保真几何和视差。
We introduce RealmDreamer, a technique for generating forward-facing 3D scenes from text descriptions. Our method optimizes a 3D Gaussian Splatting representation to match complex text prompts using pretrained diffusion models. Our key insight is to leverage 2D inpainting diffusion models conditioned on an initial scene estimate to provide low variance supervision for unknown regions during 3D distillation. In conjunction, we imbue high-fidelity geometry with geometric distillation from a depth diffusion model, conditioned on samples from the inpainting model. We find that the initialization of the optimization is crucial, and provide a principled methodology for doing so. Notably, our technique doesn't require video or multi-view data and can synthesize various high-quality 3D scenes in different styles with complex layouts. Further, the generality of our method allows 3D synthesis from a single image. As measured by a comprehensive user study, our method outperforms all existing approaches, preferred by 88-95%. Project Page: https://realmdreamer.github.io/
研究动机与目标
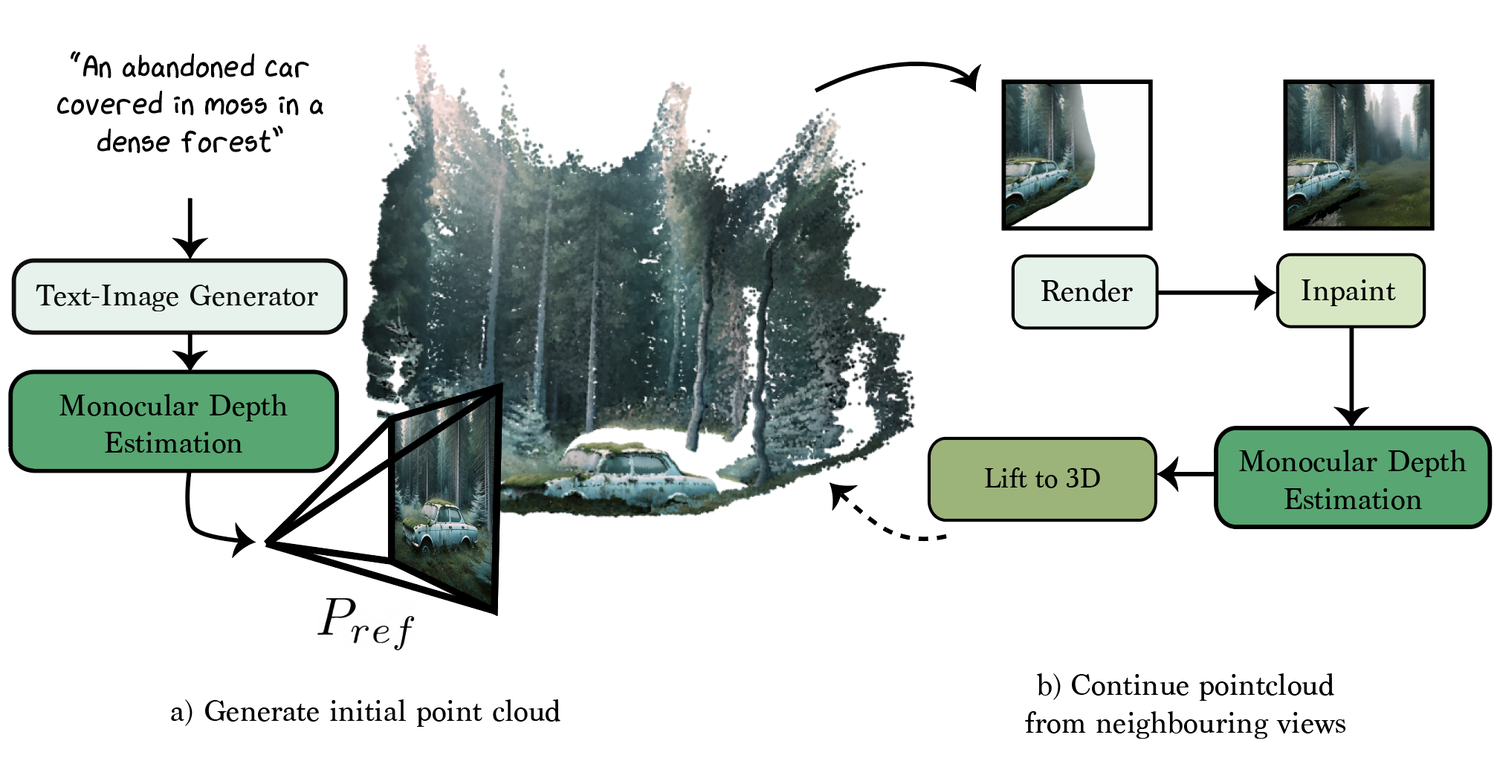
- 使用 3D Gaussian splatting 实现从文本到场景尺度的 3D 场景合成。
- 利用 2D diffusion priors 进行稳健初始化和多视图一致性。
- 将 inpainting 与 depth diffusion priors 融入,填充被遮挡区域并改善几何。
- 提供带有 sharpening 与 opacity 正则化的微调阶段,以提升细节。
提出的方法
- 从文本提示初始化面向场景级别的 3D Gaussian Splatting 表示,使用 2D diffusion priors 与单目深度;计算遮挡体积并与点云结合。
- 将场景完成视为一个 inpainting 问题,使用带有文本、图像和遮挡掩码条件的 2D inpainting diffusion 模型;通过联合潜在空间与像素空间损失,以及感知与锚点项进行优化。
- 通过使用干净的修补样本作为条件,利用图像条件深度扩散模型提取深度信息,并基于皮尔逊相关性优化深度损失。
- 进行带个性化文本到图像扩散模型的微调阶段,以提升细节锐化,同时进行不透明度正则化以鼓励二值不透明,并在样本上应用锐化滤镜以改善最终渲染质量。
- 实现依赖 PyTorch3D、NeRFStudio、Stable Diffusion 2.0、Marigold depth estimation、和 DepthAnything 的缩放用于绝对深度的实现。
![Figure 2 : Our method, compared to the state-of-the-art ProlificDreamer [ 66 ] , shows significant improvements. ProlificDreamer’s public results, with outward-looking cameras from a scene-independent sphere, result in poor depth quality. Even with a complex training trajectory, ProlificDreamer yiel](https://ar5iv.labs.arxiv.org/html/2404.07199/assets/figures/vsd_failure.png)
实验结果
研究问题
- RQ1如何在无视频或多视图数据的情况下,通过文本提示实现面向场景级别的 3D 场景生成?
- RQ2是否可以将 2D diffusion priors(修补与深度)蒸馏到 3D Gaussian Splatting 表示中,以在不同视图间产生一致的几何?
- RQ3稳健初始化与后续修补/深度蒸馏对场景保真度及视差真实感的影响如何?
- RQ4微调和锐化阶段是否在提升细节的同时保持与文本提示的对齐?
- RQ5单图到 3D 的生成能否通过所提流程有效扩展?
主要发现
- RealmDreamer 在基于文本的 3D 场景生成方面实现了对视差和高保真几何的最先进定性结果。
- 相较于基线,它产生更连贯的几何结构和更清晰的渲染,减少云雾状或过度饱和等伪影。
- 基于 CLIP 的评估显示 RealmDreamer 在逐场景层面上对提示的对齐度高于 Text2Room、DreamFusion 和 ProlificDreamer。
- 消融研究证实了 inpainting diffusion、深度先验、鲁棒初始化和锐化对最终质量的重要性。
- 该方法在与带说明文本的提示配对时,也能够从单张图像生成 3D 场景。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。