[论文解读] Recent Advances in Named Entity Recognition: A Comprehensive Survey and Comparative Study
本综述回顾了最近的 NER 方法,包括基于图的、基于 Transformer 的模型、LLMs 和低资源方法,并提供对流行框架的跨数据集比较。
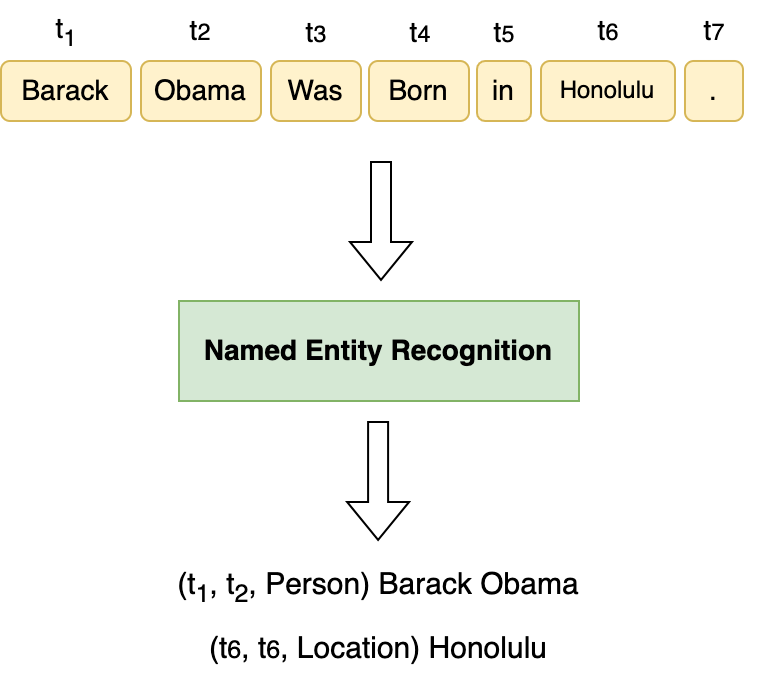
Named Entity Recognition seeks to extract substrings within a text that name real-world objects and to determine their type (for example, whether they refer to persons or organizations). In this survey, we first present an overview of recent popular approaches, including advancements in Transformer-based methods and Large Language Models (LLMs) that have not had much coverage in other surveys. In addition, we discuss reinforcement learning and graph-based approaches, highlighting their role in enhancing NER performance. Second, we focus on methods designed for datasets with scarce annotations. Third, we evaluate the performance of the main NER implementations on a variety of datasets with differing characteristics (as regards their domain, their size, and their number of classes). We thus provide a deep comparison of algorithms that have never been considered together. Our experiments shed some light on how the characteristics of datasets affect the behavior of the methods we compare.
研究动机与目标
- 定义 NER 任务及其在各领域中的应用。
- 综述并对现代 NER 方法进行分类,重点是 transformers 与 LLMs。
- 强调为低资源/低标注设置而设计的方法。
- 提供对不同数据集上流行 NER 框架的实验比较。
提出的方法
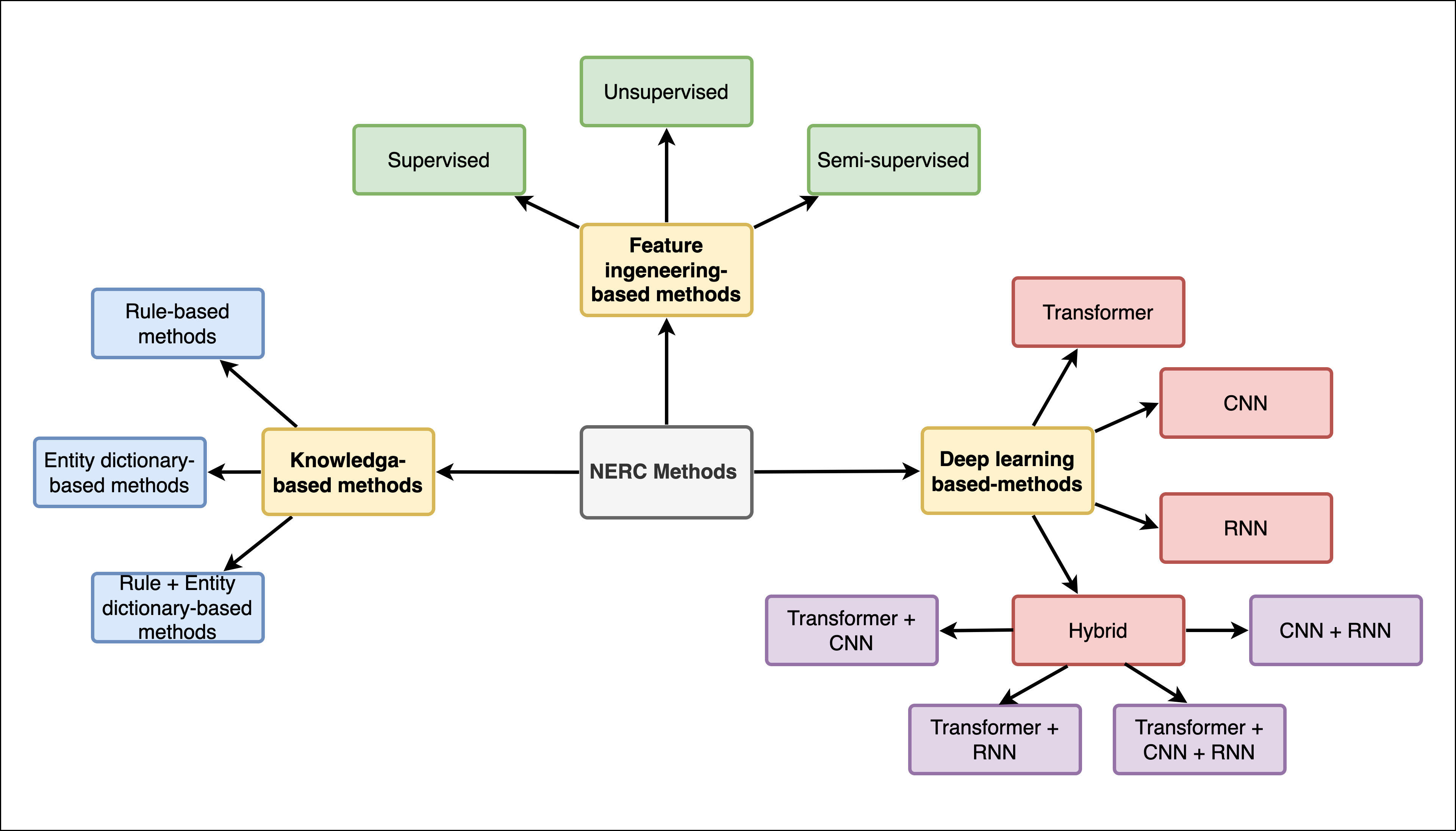
- 将方法分为知识驱动、特征工程、监督学习、深度学习(CNN/RNN/混合)、基于变换器的编码器,以及大语言模型(LLM)方法。
- 描述数据表示,包括词嵌入和字符嵴嵌入,以及上下文编码策略(CNN、RNN、BiLSTMs 与 transformers)。
- 讨论标签解码架构(CRF、MLP、指针网络)及其对序列标注的影响。
- 总结基于变换器的模型(BERT、DistilBERT、RoBERTa)及其在 NER 的适应,例如多语言和领域特定微调。
- 解释基于 LLM 的 NER 方法(文本生成框架、少样本提示),并给出研究的观察结果表。
实验结果
研究问题
- RQ1NER 的主导方法趋势是什么(知识驱动、监督学习、深度学习、transformers、LLMs),它们如何演变?
- RQ2数据集特征(领域、规模、类别数量)如何影响 NER 方法的相对性能?
- RQ3在低资源或标注稀缺的情境中,NER 的挑战和有效性如何?
- RQ4对于跨语言和领域的 NER 任务,变换器编码器和 LLMs 与传统架构相比有何差异?
主要发现
- 该调查强调了 transformer 基于编码器和 LLM 在 NER 中日益突出的地位。
- 它强调了为低标注设置量身定制的方法,并讨论它们的性能影响。
- 跨数据集的实验比较揭示数据集属性如何影响方法的有效性。
- 基于 LLM 的 NER 方法在少数-shot 和低资源场景中显示出潜力,有时甚至可以与有监督基线相媲美。
- 在 NER 领域评估方案和语料库的同时,还回顾了多种工具和预训练模型资源。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。