[论文解读] Recent advances in text embedding: A Comprehensive Review of Top-Performing Methods on the MTEB Benchmark
本综述分析在 MTEB 上表现最佳的通用文本嵌入,详述来自 2023–2024 的数据、损失与基于 LLM 的方法,并概述趋势与差距。
Text embedding methods have become increasingly popular in both industrial and academic fields due to their critical role in a variety of natural language processing tasks. The significance of universal text embeddings has been further highlighted with the rise of Large Language Models (LLMs) applications such as Retrieval-Augmented Systems (RAGs). While previous models have attempted to be general-purpose, they often struggle to generalize across tasks and domains. However, recent advancements in training data quantity, quality and diversity; synthetic data generation from LLMs as well as using LLMs as backbones encourage great improvements in pursuing universal text embeddings. In this paper, we provide an overview of the recent advances in universal text embedding models with a focus on the top performing text embeddings on Massive Text Embedding Benchmark (MTEB). Through detailed comparison and analysis, we highlight the key contributions and limitations in this area, and propose potentially inspiring future research directions.
研究动机与目标
- 通过回顾由 MTEB 基准优先考虑的通用文本嵌入及其与检索、分类、聚类和其他任务的相关性来推动本研究。
- 将文献分为数据导向、损失导向和 LLM 导向三大类,以澄清通用嵌入的发展方向。
- 概述主要架构(如 GTE、BGE、E5、UAE、Multilingual-E5)以及数据质量、多样性和训练信号如何影响性能。
- 强调 MTEB 的多任务、多语言评估设置如何推动跨任务泛化的模型设计。
提出的方法
- 讨论通过大规模、多样化的预训练和高质量微调数据来提升通用嵌入的以数据为中心的策略(例如 CCPairs、基于 CC 的来源、多数据集混合)。
- 描述改进对比学习并解决梯度问题的损失函数创新(例如改进的 InfoNCE 变体、UAE 中的角度优化)。
- 解释硬负样本、批内负样本,以及知识蒸馏在预训练和微调阶段的作用。
- 概述 LLMs 如何用作数据标注者或作为骨干模型以提升通用性和多语言性(例如合成数据、指令微调、跨编码器蒸馏)。
- 总结在各方法中使用的骨干模型和训练方案(BERT 家族、RoBERTa、长距离变换器,以及仅解码器的 LLMs)。
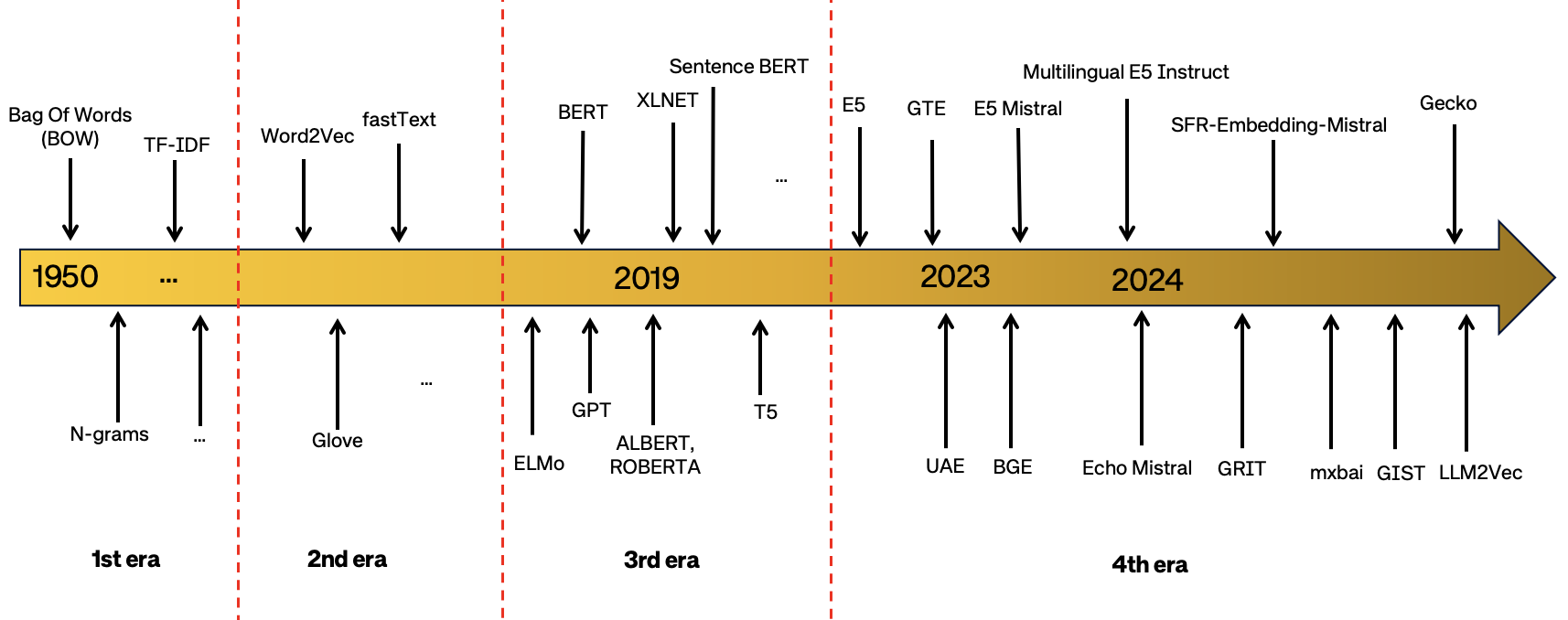
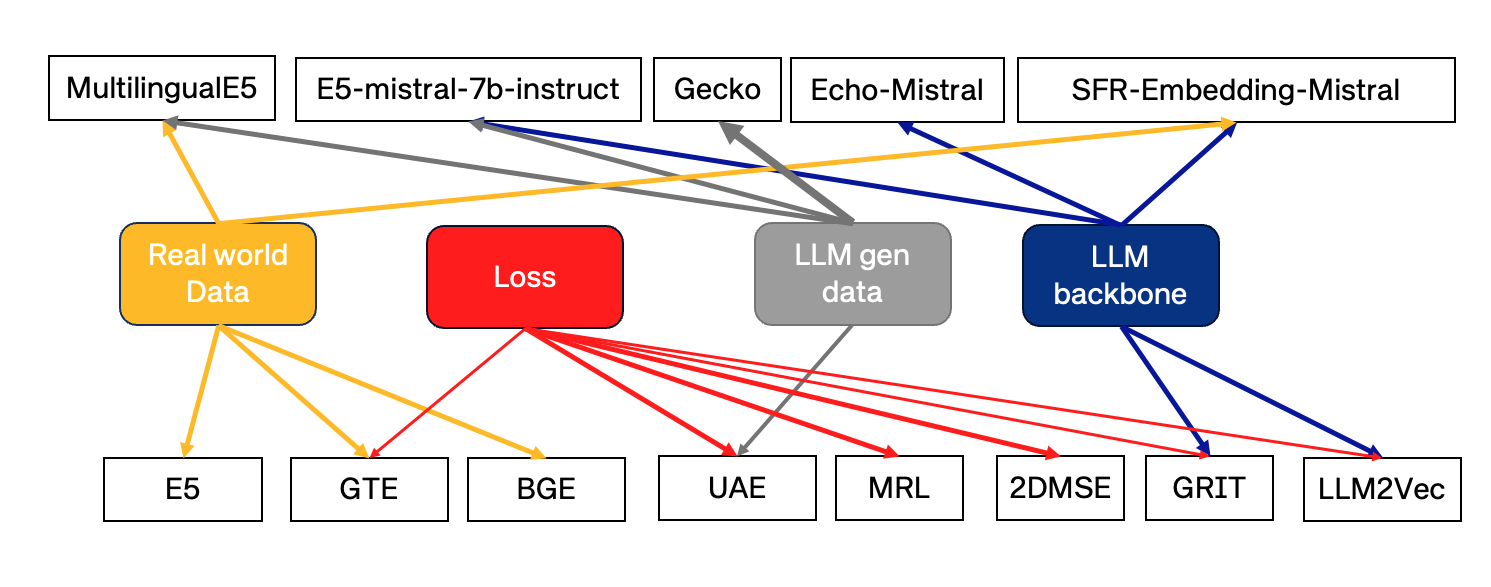
实验结果
研究问题
- RQ1在 MTEB 背景下,通用文本嵌入的定义是什么,以及数据、损失和模型选择如何影响跨任务泛化?
- RQ2顶尖方法如何利用数据质量、多样性和合成数据来提升在 58 个数据集和 112 种语言上的性能?
- RQ3当前以数据、损失和 LLM 为重点的方法在通用嵌入方面的局限性与权衡是什么?
- RQ4在多任务和多语言方面,LLMs 作为骨干或标注者在提升通用嵌入方面的有效程度到何种程度?
- RQ5哪些未来方向可以进一步提升文本嵌入的通用性和效率?
主要发现
- 在 MTEB 上的顶尖模型依赖于大规模、多样化的预训练和高质量的微调数据来实现广泛的任务覆盖。
- 损失创新与梯度问题的处理(如角度优化)有助于改进优化和嵌入质量。
- 批内和硬负样本采样,以及来自跨编码器的蒸馏,提升检索效果和样本质量嵌入。
- LLMs 正在越来越多地作为数据标注者和骨干模型来提升多语言和多任务性能。
- Multilingual-E5 及相关模型展示了多语言数据混合和指令数据对跨语言通用性的价值。
- 所调查的方法在通用文本嵌入方面显示出显著改善,但在对未见任务和领域的泛化方面仍然存在挑战。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。