[论文解读] Reconstructing the Mind's Eye: fMRI-to-Image with Contrastive Learning and Diffusion Priors
MindEye 将 fMRI 数据解码为既检索又重建图像,通过将大脑活动映射到 CLIP 图像空间,采用对比学习与扩散先验,实现最先进的检索与重建。
We present MindEye, a novel fMRI-to-image approach to retrieve and reconstruct viewed images from brain activity. Our model comprises two parallel submodules that are specialized for retrieval (using contrastive learning) and reconstruction (using a diffusion prior). MindEye can map fMRI brain activity to any high dimensional multimodal latent space, like CLIP image space, enabling image reconstruction using generative models that accept embeddings from this latent space. We comprehensively compare our approach with other existing methods, using both qualitative side-by-side comparisons and quantitative evaluations, and show that MindEye achieves state-of-the-art performance in both reconstruction and retrieval tasks. In particular, MindEye can retrieve the exact original image even among highly similar candidates indicating that its brain embeddings retain fine-grained image-specific information. This allows us to accurately retrieve images even from large-scale databases like LAION-5B. We demonstrate through ablations that MindEye's performance improvements over previous methods result from specialized submodules for retrieval and reconstruction, improved training techniques, and training models with orders of magnitude more parameters. Furthermore, we show that MindEye can better preserve low-level image features in the reconstructions by using img2img, with outputs from a separate autoencoder. All code is available on GitHub.
研究动机与目标
- 证明大脑活动可以映射到高维的多模态嵌入(例如 CLIP 图像空间)以用于图像重建和检索。
- 开发专门的检索和重建子模块,以同时优化这两项任务。
- 表明在低数据情形下,具有大量参数的 MLP 主干在不产生过拟合的情况下提升性能。
- 利用扩散先验来对齐分离的多模态嵌入并实现高保真度的图像生成。
- 展示在大型候选集合(如 LAION-5B)中也能检索到原始图像的能力。
提出的方法
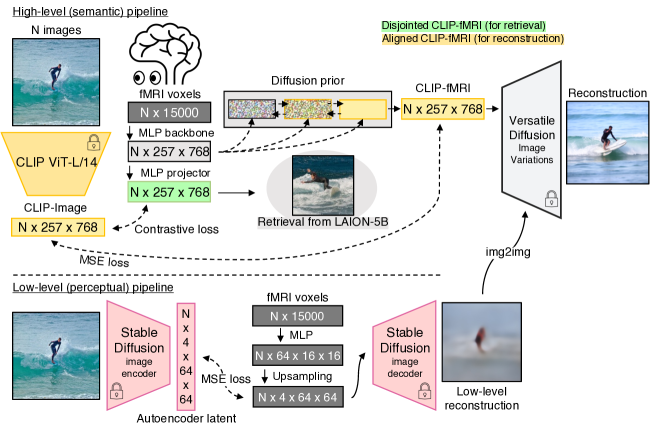
- 两条并行流程(从高级语义到 CLIP 图像空间,以及从低级感知到 VAE 空间)。
- 高级流程使用 MLP 主干将 fMRI 体素映射到 CLIP 嵌入,再通过扩散先验进行重建并使用投影器进行检索。
- 低级流程将体素映射到 Stable Diffusion 的 VAE 嵌入,产生模糊重建,通过 img2img 细化得到改进。
- 训练使用双向 CLIP 损失(BiMixCo)用于投影器,扩散先验使用 MSE 损失,SoftCLIP 作为蒸馏式软目标信号。
- 一个扩散先验从头开始训练,以在输入到预训练图像生成器之前将大脑嵌入与 CLIP 图像嵌入对齐。
- 训练将 BiMixCo 与 SoftCLIP 结合起来,训练过程在完成三分之一后从 BiMixCo 转向 SoftCLIP。
- 由于其模块化设计,该模型可以在单个 A100 GPU 上训练 240 轮,并且在大参数量下也不会过拟合地扩展。
![Figure 1: Example images reconstructed from human brain activity corresponding to passive viewing of natural scenes. Reconstructions depict outputs from Versatile Diffusion [ 6 ] given CLIP fMRI embeddings generated by MindEye for Subject 1. See Figure 4 and Appendix A.4 for more samples.](https://ar5iv.labs.arxiv.org/html/2305.18274/assets/x1.png)
实验结果
研究问题
- RQ1能否将 fMRI 活动映射到 CLIP 图像嵌入,以实现准确的图像重建和检索?
- RQ2专门化的检索(对比学习)和重建(扩散为基础)子模块是否优于统一的单一空间方法?
- RQ3在低数据情境下,大型、参数丰富的 MLP 主干是否在不发生过拟合的情况下提升性能?
- RQ4扩散先验是否能够缓解大脑和图像模态之间嵌入的分离性,从而提升重建质量?
- RQ5是否可以使用脑源嵌入从大型候选库(如 LAION-5B)中检索到原始图像?
主要发现
- MindEye 在图像检索和脑检索方面都达到最先进水平,包括在 982 张测试图像中对 Subject 1 的 top-1 检索准确率超过 90%。
- 与扩散先验配对的高级语义流程在使用如 Versatile Diffusion 的预训练图像生成器时能产生高质量的重建。
- 具有残差块的大型 MLP 主干能提升检索性能,随着模型深度增加,跳连接变得至关重要。
- BiMixCo 搭配 SoftCLIP在检索与重建之间提供最佳平衡,尽管单独的 BiMixCo 提供最强的检索能力;解耦损失有助于权衡。
- 通过映射到 Stable Diffusion 的 VAE 潜在空间并随后的 img2img 精炼实现的低级重建,达到行业领先的低级图像指标。
- 检索嵌入保留了细粒度的样本级信息,使得在像 LAION-5B 这样的超大规模候选池中也能实现精确图像检索。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。