[论文解读] Redefining "Hallucination" in LLMs: Towards a psychology-informed framework for mitigating misinformation
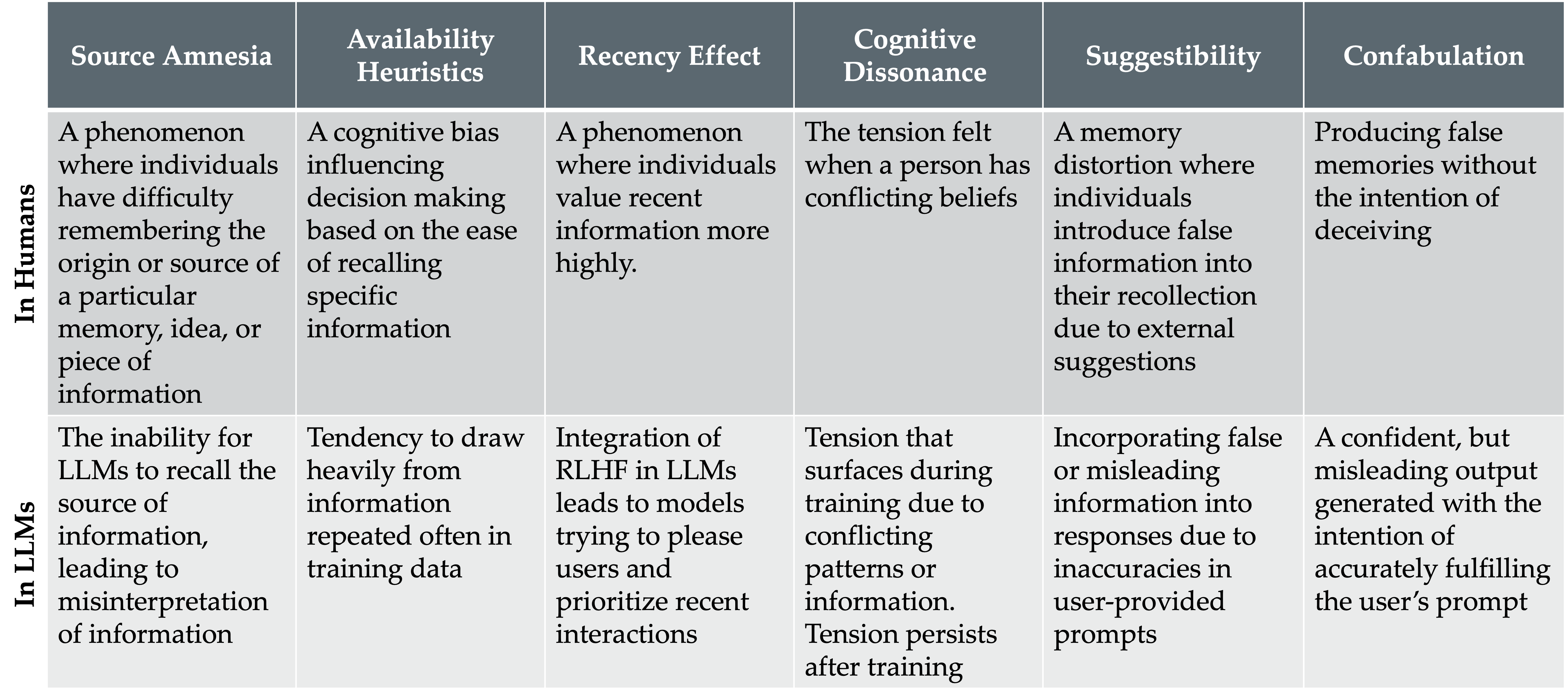
本文认为对大型语言模型错误常用术语“hallucination”具有误导性,并提出基于心理学的分类法(source amnesia、recency、availability、suggestibility、cognitive dissonance、confabulation),并给出以元认知为灵感的缓解策略。
In recent years, large language models (LLMs) have become incredibly popular, with ChatGPT for example being used by over a billion users. While these models exhibit remarkable language understanding and logical prowess, a notable challenge surfaces in the form of "hallucinations." This phenomenon results in LLMs outputting misinformation in a confident manner, which can lead to devastating consequences with such a large user base. However, we question the appropriateness of the term "hallucination" in LLMs, proposing a psychological taxonomy based on cognitive biases and other psychological phenomena. Our approach offers a more fine-grained understanding of this phenomenon, allowing for targeted solutions. By leveraging insights from how humans internally resolve similar challenges, we aim to develop strategies to mitigate LLM hallucinations. This interdisciplinary approach seeks to move beyond conventional terminology, providing a nuanced understanding and actionable pathways for improvement in LLM reliability.
研究动机与目标
- 批判性评估在 LLMs 中使用的术语 'hallucination' 及其描述模型输出的适切性。
- 提出基于心理学的分类法,将 LLM 错误映射到认知偏差和记忆现象。
- 提出受人类元认知和源监控启发的具体缓解策略。
- 倡导利用心理学构念来改进 LLM 可靠性的有针对性缓解路径。
提出的方法
- 回顾并综合现有对 LLM hallucinations 的定义和分类法。
- 将识别到的现象映射到心理学概念:source amnesia、recency effect、availability heuristics、suggestibility、cognitive dissonance、confabulation。
- 主张并描述一个以心理学为基础的分类法,作为对任务特定 hallucination 标签的替代。
- 讨论潜在的元认知启发策略(增强源归因、源监控、反思性处理、人工元认知)。
- 引用关于自我反省和自我探询的相关工作,作为所提缓解措施的对照。

实验结果
研究问题
- RQ1How well does the term 'hallucination' capture the phenomena observed in LLM outputs?
- RQ2Can a psychology-based taxonomy more precisely categorize LLM errors than existing intrinsic/extrinsic or task-specific labels?
- RQ3What mitigation strategies inspired by human metacognition could reduce LLM misinformation?
- RQ4Which psychological constructs best align with different error types in LLMs to inform targeted fixes?
主要发现
- A psychology-informed taxonomy aligns LLM error types with known cognitive biases and memory phenomena.
- Source amnesia、recency effect、availability heuristics、suggestibility、cognitive dissonance、和 confabulation 映射到不同但互相关联的 LLM 失效模式。
- Metacognition-inspired strategies (source attribution、monitoring、reflective processing) are proposed as practical avenues to mitigate misinformation in LLMs.
- Self-reflection and self-inquiry approaches from related works demonstrate potential for reducing hallucination-like outputs.
- The paper argues for moving beyond 'hallucination' terminology to enable more precise, targeted mitigation.
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。