[论文解读] Reflexion: Language Agents with Verbal Reinforcement Learning
Reflexion 通过基于环境反馈生成口头反思来让语言代理从试错中学习,将其存储在情节记忆中以指导未来的尝试,在编码、推理和决策基准上实现无需权重更新的最先进结果。
Large language models (LLMs) have been increasingly used to interact with external environments (e.g., games, compilers, APIs) as goal-driven agents. However, it remains challenging for these language agents to quickly and efficiently learn from trial-and-error as traditional reinforcement learning methods require extensive training samples and expensive model fine-tuning. We propose Reflexion, a novel framework to reinforce language agents not by updating weights, but instead through linguistic feedback. Concretely, Reflexion agents verbally reflect on task feedback signals, then maintain their own reflective text in an episodic memory buffer to induce better decision-making in subsequent trials. Reflexion is flexible enough to incorporate various types (scalar values or free-form language) and sources (external or internally simulated) of feedback signals, and obtains significant improvements over a baseline agent across diverse tasks (sequential decision-making, coding, language reasoning). For example, Reflexion achieves a 91% pass@1 accuracy on the HumanEval coding benchmark, surpassing the previous state-of-the-art GPT-4 that achieves 80%. We also conduct ablation and analysis studies using different feedback signals, feedback incorporation methods, and agent types, and provide insights into how they affect performance.
研究动机与目标
- 为传统强化学习提供一个轻量级替代方案,该方案利用口头反馈而非权重更新。
- 表明自我反思和情节记忆能够提升在决策、推理和编程任务中的任务表现。
- 展示在多环境、多语言上的可扩展性,包括一个新的 LeetcodeHardGym 基准。
- 提供消融研究以理解反馈类型和记忆如何影响性能。
提出的方法
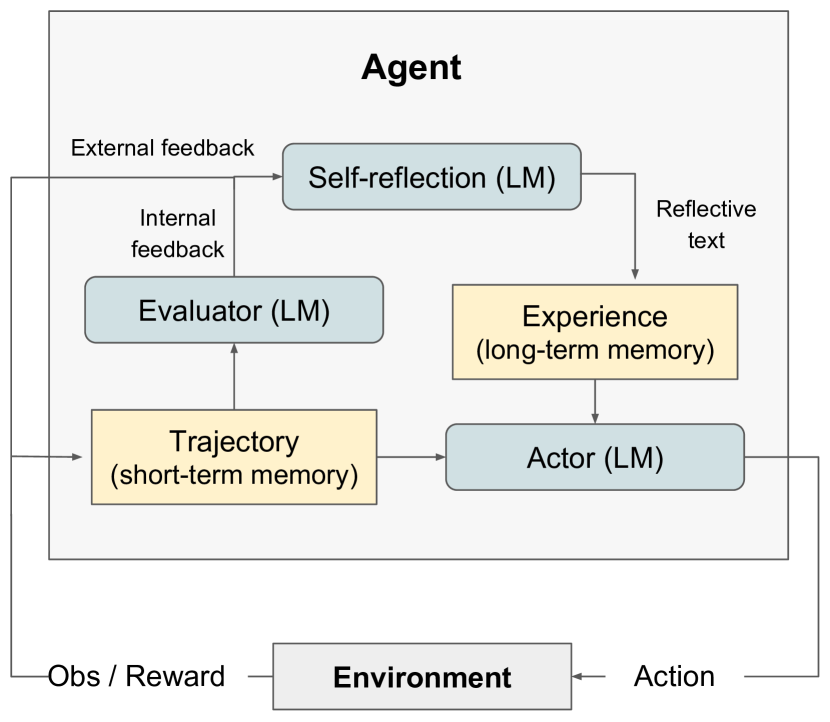
- 提出一个模块化的 Reflexion 框架,包含三种模型:Actor(基于 LLM 的文本与行动生成器)、Evaluator(对 Actor 输出进行评分)、Self-Reflection(生成口头反馈以增强记忆)。
- 将环境反馈转化为口头反思并存储在记忆缓冲区中,以影响未来的情节。
- 使用短期(轨迹)和长期(自我反思)记忆来条件化 Actor 的决策。
- 尝试各种反馈信号(二元、启发式、自我评估)以及不同的任务类型(决策、推理、编程)。
- 将 Reflexion 算法描述为一个迭代循环:每次试验产生一个轨迹、一个 Evaluator 分数,以及一个被追加到记忆中的自我反思,以供后续试验使用。

实验结果
研究问题
- RQ1口头自我反思和情节记忆是否能够使基于LLM的代理从稀疏/试错反馈中学习,而无需基于梯度的微调?
- RQ2不同的反馈信号和记忆配置如何影响决策、推理和编程任务的性能?
- RQ3在既定基准和一个新的代码生成环境上,Reflexion 的提升有哪些?
- RQ4Reflexion 在编程任务中跨语言和工具使用是否具有鲁棒性?
主要发现
- 与强基线相比,Reflexion 在决策、推理和编程任务上提升性能。
- 在 AlfWorld 的决策任务中,Reflexion 结合简单的启发式自我评估取得显著提升,在 12 次试验中达到接近完美的表现。
- 在 HotPotQA 推理任务中,Reflexion 显著优于基线,对 CoT 和 ReAct 变体有显著提升。
- 在人类评估编程(Python 和 Rust)中,Reflexion 实现了最先进的 pass@1 分数,特别是使用 GPT-4 的 Python HumanEval 达到 91.0,超过先前的 SOTA。
- LeetcodeHardGym 展示了 Reflexion 处理高难度编码问题的能力,采用自生成的单元测试方法,取得强劲的 pass@1 结果。
- 消融研究显示自我反思和记忆的重要性,移除任一组件时性能会下降。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。