[论文解读] Reimagining Synthetic Tabular Data Generation through Data-Centric AI: A Comprehensive Benchmark
本文提出一个以数据为中心的 AI 框架,用于评估和引导合成表格数据生成,结果表明仅有统计保真度不足以评估,数据特征分型能够在多种生成模型中提升下游效用。
Synthetic data serves as an alternative in training machine learning models, particularly when real-world data is limited or inaccessible. However, ensuring that synthetic data mirrors the complex nuances of real-world data is a challenging task. This paper addresses this issue by exploring the potential of integrating data-centric AI techniques which profile the data to guide the synthetic data generation process. Moreover, we shed light on the often ignored consequences of neglecting these data profiles during synthetic data generation -- despite seemingly high statistical fidelity. Subsequently, we propose a novel framework to evaluate the integration of data profiles to guide the creation of more representative synthetic data. In an empirical study, we evaluate the performance of five state-of-the-art models for tabular data generation on eleven distinct tabular datasets. The findings offer critical insights into the successes and limitations of current synthetic data generation techniques. Finally, we provide practical recommendations for integrating data-centric insights into the synthetic data generation process, with a specific focus on classification performance, model selection, and feature selection. This study aims to reevaluate conventional approaches to synthetic data generation and promote the application of data-centric AI techniques in improving the quality and effectiveness of synthetic data.
研究动机与目标
- 强调纯粹统计保真在合成表格数据生成中的局限性。
- 提出一个数据为中心的 AI 框架,用于对数据进行特征分型并引导合成数据创建。
- 在十一个数据集上对五种最先进的表格数据生成器进行基准评测。
- 评估数据为中心的预处理/后处理对下游分类、模型选择和特征选择的影响。
- 为将数据为中心的洞见整合到合成数据工作流中提供切实可行的建议。
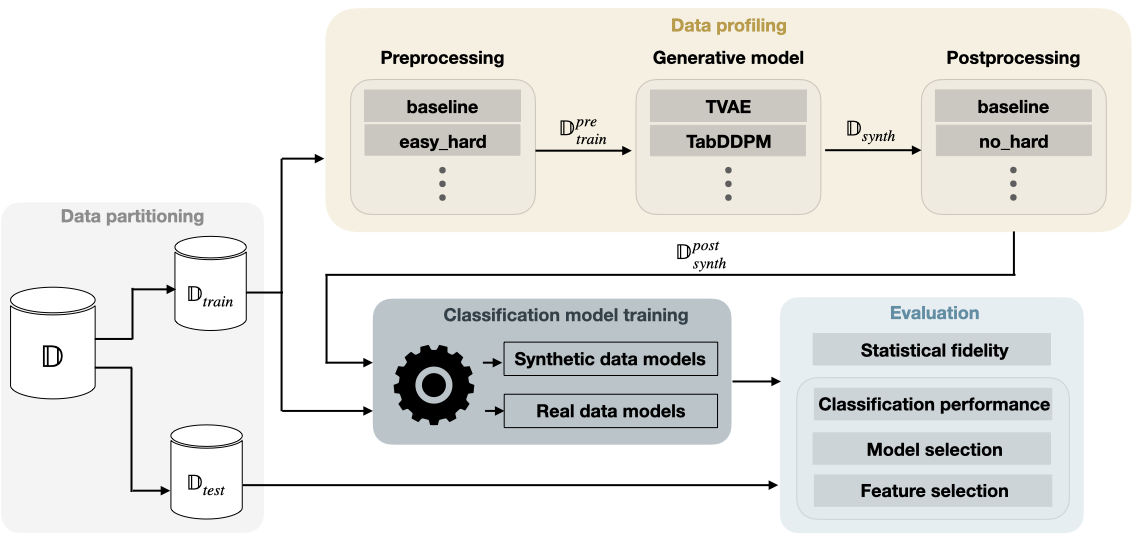
提出的方法
- 用 Cleanlab、Data-IQ、Data Maps 等方法定义数据为中心的分析(简单/模糊/困难)。
- 在训练生成模型前对真实训练数据进行预处理以创建分析画像。
- 在不同数据画像上训练独立的生成模型并按比例组合合成数据。
- 对合成数据应用后处理策略(基线与去除困难样本)。
- 在真实数据和合成数据上训练分类器,并通过下游评估(AUROC、排序)进行比较。
- 使用散度量(逆 KL、MMD、Wasserstein)评估统计保真度,并扩展到数据效用任务。
![Figure 1: Measures of data-centric profiling (A) better reflect the downstream performance of generative models (B) than measures of statistical fidelity (C). Assessed on the Adult dataset [ 16 ] using five different generative models A) Proportion easy examples in the generated datasets identified](https://ar5iv.labs.arxiv.org/html/2310.16981/assets/figs/poc_proportions.png)
实验结果
研究问题
- RQ1统计保真度是否能够单独预测合成表格数据的下游效用?
- RQ2数据为中心的分析是否能提升合成数据在分类、模型选择和特征选择上的真实感和效用?
- RQ3在数据画像引导下,不同生成模型在下游任务上的表现如何?
- RQ4标签噪声对数据为中心的预处理/后处理有效性有何影响?
主要发现
| Generative Model | Classification Model | Selection | Feature Selection | Statistical fidelity |
|---|---|---|---|---|
| Real data | 0.866 (0.855, 0.877) | 1.0 | 1.0 | 1.0 |
| bayesian_network | 0.622 (0.588, 0.656) | 0.155 (0.055, 0.264) | 0.091 (-0.001, 0.188) | 0.998 (0.998, 0.999) |
| ctgan | 0.797 (0.769, 0.823) | 0.519 (0.457, 0.579) | 0.63 (0.557, 0.691) | 0.979 (0.967, 0.987) |
| ddpm | 0.813 (0.781, 0.844) | 0.508 (0.446, 0.573) | 0.635 (0.546, 0.718) | 0.846 (0.668, 0.972) |
| nflow | 0.737 (0.713, 0.761) | 0.354 (0.288, 0.427) | 0.415 (0.34, 0.485) | 0.975 (0.968, 0.981) |
| tvae | 0.792 (0.764, 0.818) | 0.506 (0.436, 0.565) | 0.675 (0.63, 0.722) | 0.966 (0.953, 0.978) |
- 统计保真度不足以单独衡量合成数据在下游任务中的有用性。
- 不同的生成模型(CTGAN、TabDDPM、TVAE)在不同任务上表现不同(模型选择、特征选择、分类)。
- 数据为中心的预处理和后处理通常能提升大多数模型和数据集的分类、模型选择和特征选择效用,尽管在统计保真度上往往有一定损失。
- 在不同标签噪声水平下,数据为中心的处理收益仍然存在,但在高噪声水平(如 >8%)时有所减弱。
- 没有单一生成器在所有任务上占优;CTGAN 和 TVAE 往往在保真度与下游效用之间提供更有利的权衡。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。