[论文解读] Reinforcement Learning-based Counter-Misinformation Response Generation: A Case Study of COVID-19 Vaccine Misinformation
本文提出 MisinfoCorrect,一种基于强化学习的反误信息响应生成器,使用两种新颖数据集(野外数据集和众包数据集)来生成礼貌、有据、且有驳斥性的对COVID-19疫苗错误信息的回应,并显示其优于基线。
The spread of online misinformation threatens public health, democracy, and the broader society. While professional fact-checkers form the first line of defense by fact-checking popular false claims, they do not engage directly in conversations with misinformation spreaders. On the other hand, non-expert ordinary users act as eyes-on-the-ground who proactively counter misinformation -- recent research has shown that 96% counter-misinformation responses are made by ordinary users. However, research also found that 2/3 times, these responses are rude and lack evidence. This work seeks to create a counter-misinformation response generation model to empower users to effectively correct misinformation. This objective is challenging due to the absence of datasets containing ground-truth of ideal counter-misinformation responses, and the lack of models that can generate responses backed by communication theories. In this work, we create two novel datasets of misinformation and counter-misinformation response pairs from in-the-wild social media and crowdsourcing from college-educated students. We annotate the collected data to distinguish poor from ideal responses that are factual, polite, and refute misinformation. We propose MisinfoCorrect, a reinforcement learning-based framework that learns to generate counter-misinformation responses for an input misinformation post. The model rewards the generator to increase the politeness, factuality, and refutation attitude while retaining text fluency and relevancy. Quantitative and qualitative evaluation shows that our model outperforms several baselines by generating high-quality counter-responses. This work illustrates the promise of generative text models for social good -- here, to help create a safe and reliable information ecosystem. The code and data is accessible on https://github.com/claws-lab/MisinfoCorrect.
研究动机与目标
- 通过产生有效、基于证据的反应推动众包驱动的错误信息纠正。
- 创建两份社交媒体误信息帖子及反回应的标注数据集,来源于社交媒体和众包。
- 开发一个强化学习框架,在保持流畅性和相关性的同时,对礼貌、驳斥和证据给予奖励。
提出的方法
- 构建两份数据集:一份在野 Twitter 派生数据集,包含 754 对 misinfo-counterreply;另一份为 591 条来自众包的反回应数据集。
- 对反应进行属性标注:驳斥、证据和礼貌;报告分布。
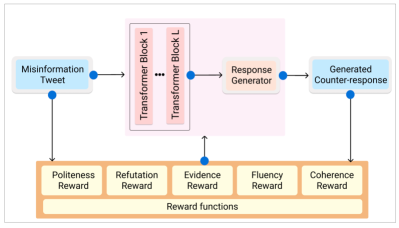
- 开发 MisinfoCorrect,一个基于 GPT-2 的生成器,使用 DialoGPT 权重进行微调,并用 RL 训练,使用复合奖励。
- 将状态定义为误信息帖子,行动定义为生成的反回应,策略为基于Transformer的生成器。
- 设计奖励包括:礼貌、驳斥、证据、流利度(逆困惑度)以及连贯性(与帖子语义相似度)。
- 总奖励 r = α*r_politeness + β*r_refutation + γ*r_evidence + θ*r_fluency + λ*r_coherence;使用奖励增强目标 L(θ) = -r*log p(ĉ|m) 进行训练。
- 以 DialoGPT 权重初始化,并使用成对数据的热启动策略;用 Adam 进行优化。

实验结果
研究问题
- RQ1RQ1: 所提出的模型是否能够生成具有理想特性的一流反回应?
- RQ2RQ2: 在野外数据 vs 众包数据对生成质量有何影响?
主要发现
- 总共创建了两个大型数据集:共 1,345 条反误信息回应(754 对社交媒体对话/对;591 条众包生成)。
- MisinfoCorrect 在生成高质量的反回应方面优于五个基线。
- 礼貌、驳斥和证据通过定制奖励在 RL 设置中显式优化。
- 该方法证明了学习基于证据的、对 COVID-19 疫苗误信息的尊重性反回应的可行性。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。