[论文解读] Relating the Partial Dependence Plot and Permutation Feature Importance to the Data Generating Process
该论文将 Partial Dependence (PD) 和 Permutation Feature Importance (PFI) 正规化为对 ground truth DGP 属性的估计量,并发展了考虑模型学习方差的方差与置信区间方法。它引入 learner-PD 和 learner-PFI 以捕捉来自模型重新拟合的不确定性。
Scientists and practitioners increasingly rely on machine learning to model data and draw conclusions. Compared to statistical modeling approaches, machine learning makes fewer explicit assumptions about data structures, such as linearity. However, their model parameters usually cannot be easily related to the data generating process. To learn about the modeled relationships, partial dependence (PD) plots and permutation feature importance (PFI) are often used as interpretation methods. However, PD and PFI lack a theory that relates them to the data generating process. We formalize PD and PFI as statistical estimators of ground truth estimands rooted in the data generating process. We show that PD and PFI estimates deviate from this ground truth due to statistical biases, model variance and Monte Carlo approximation errors. To account for model variance in PD and PFI estimation, we propose the learner-PD and the learner-PFI based on model refits, and propose corrected variance and confidence interval estimators.
研究动机与目标
- 激发将模型解释工具与 data generating process (DGP) 联系起来的必要性。
- 将 PD 和 PFI 形式化为对 ground truth DGP 属性的估计量(DGP-PD、DGP-PFI)。
- 将 PD/PFI 的误差分解为偏差、方差(模型方差和 Monte Carlo)并提出方差修正方法。
- 区分 model-PD/PFI 与 learner-PD/learner-PFI 以考虑学习过程方差。
- 提供推断工具,包括对 PD/PFI 的修正方差估计和置信区间。
提出的方法
- 将 DGP-PD 和 DGP-PFI 定义为应用于 DGP 的真实函数 f 的 ground truth PD/PFI。
- 将 PD 和 PFI 表示为包含偏差、模型方差和 Monte Carlo 误差的估计量;推导偏差-方差分解。
- 引入 model-PD/model-PFI(固定模型)和 learner-PD/learner-PFI(对模型重新拟合进行平均)作为推断目标。
- 推导 model-PD 和 model-PFI 的方差估计量并构造点估计的置信区间。
- 提出对 learner-PD/learner-PFI 的方差修正,以更好地反映学习过程的不确定性(含 Nadeau-Bengio 型修正)。
- 讨论如何使用数据分割和多次重新拟合来计算 learner-PD/learner-PFI,以捕捉模型方差。
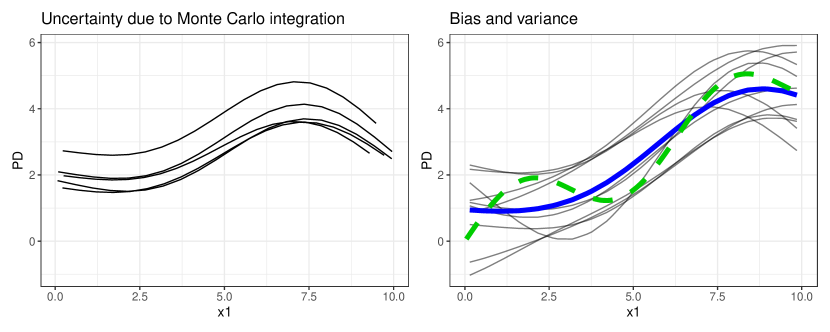
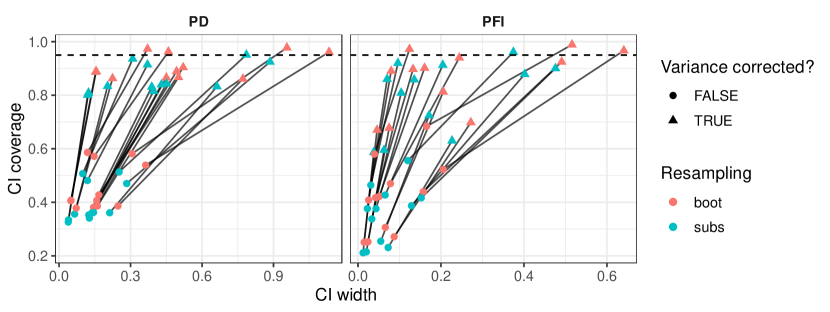
实验结果
研究问题
- RQ1PD 和 PFI 如何通过 ground truth estimands(DGP-PD、DGP-PFI)与数据生成过程相关联:
- RQ2偏差、模型方差和 Monte Carlo 误差如何影响 PD 和 PFI 的估计量,以及如何量化?
- RQ3在固定模型(model-PD/PFI)和模型重新拟合下(learner-PD/PFI)有哪些合适的方差估计量和置信区间?
- RQ4通过 learner-PD/learner-PFI 引入模型方差在实际中的解释与不确定性量化有何变化?
- RQ5在使用再采样生成多个模型拟合时,哪些修正能改善方差估计?
主要发现
- PD 和 PFI 可以被视为 ground-truth DGP 量的估计量(DGP-PD、DGP-PFI)。
- PD/PFI 的估计量包含偏差和两种方差来源:模型方差和 Monte Carlo(MC)方差。
- Model-PD/Model-PFI 仅量化 MC 方差,忽略学习过程方差,因此对 DGP 的推断有限。
- Learner-PD/Learner-PFI 对多次模型重新拟合取平均,捕捉了完整的学习过程不确定性,从而改善对 DGP 的推断。
- 对 learner-PD/PFI 的方差估计包括一个修正项,以应对使用再采样(如自助法)时的方差低估。
- 使用自由度等于模型拟合次数的 t 分布构造 learner-PD/PFI 的置信区间。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。