[论文解读] RemoteCLIP: A Vision Language Foundation Model for Remote Sensing
RemoteCLIP 是一个面向遥感的视觉-语言基础模型,通过 Box-to-Caption 和 Mask-to-Box 转换来扩展数据规模,以对齐图像-文本表示,从而在不同数据集上实现零-shot 和检索任务。
General-purpose foundation models have led to recent breakthroughs in artificial intelligence. In remote sensing, self-supervised learning (SSL) and Masked Image Modeling (MIM) have been adopted to build foundation models. However, these models primarily learn low-level features and require annotated data for fine-tuning. Moreover, they are inapplicable for retrieval and zero-shot applications due to the lack of language understanding. To address these limitations, we propose RemoteCLIP, the first vision-language foundation model for remote sensing that aims to learn robust visual features with rich semantics and aligned text embeddings for seamless downstream application. To address the scarcity of pre-training data, we leverage data scaling which converts heterogeneous annotations into a unified image-caption data format based on Box-to-Caption (B2C) and Mask-to-Box (M2B) conversion. By further incorporating UAV imagery, we produce a 12 $ imes$ larger pretraining dataset than the combination of all available datasets. RemoteCLIP can be applied to a variety of downstream tasks, including zero-shot image classification, linear probing, $ extit{k}$-NN classification, few-shot classification, image-text retrieval, and object counting in remote sensing images. Evaluation on 16 datasets, including a newly introduced RemoteCount benchmark to test the object counting ability, shows that RemoteCLIP consistently outperforms baseline foundation models across different model scales. Impressively, RemoteCLIP beats the state-of-the-art method by 9.14% mean recall on the RSITMD dataset and 8.92% on the RSICD dataset. For zero-shot classification, our RemoteCLIP outperforms the CLIP baseline by up to 6.39% average accuracy on 12 downstream datasets. Project website: https://github.com/ChenDelong1999/RemoteCLIP
研究动机与目标
- 解决遥感领域用于视觉-语言模型的预训练数据稀缺问题。
- 学习具备丰富语义的鲁棒视觉特征,并获得与之对齐的文本嵌入,以用于下游任务。
- 通过统一的图像-标题数据格式,在遥感领域实现零-shot、少样本和基于检索的应用。
- 演示数据扩展技术,以利用异构注释进行大规模预训练。
提出的方法
- 使用 CLIP 风格的对比预训练,包含图像编码器和文本编码器,以优化 InfoNCE 损失。
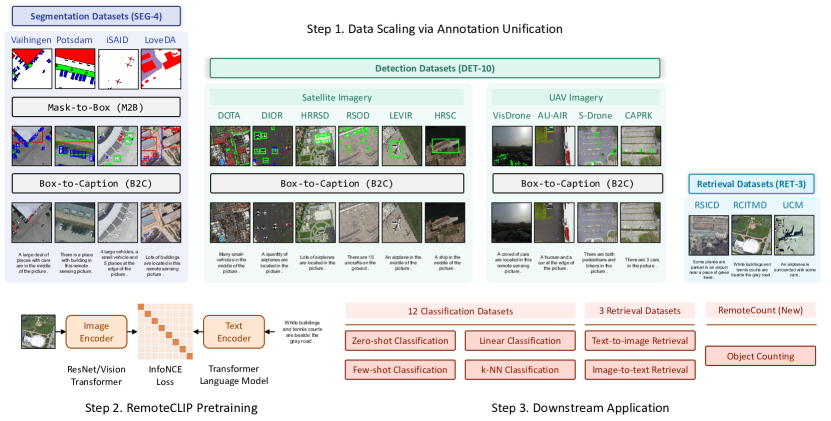
- 通过 Box-to-Caption (B2C) 生成和 Mask-to-Box (M2B) 转换来统一异构遥感注释,以创建图像-文本对。
- 通过整合 DET-10、SEG-4、RET-3 和 UAV 图像,将预训练数据规模扩展到原有开源数据集的 12 倍。
- 在 16 个下游数据集上,评估 RemoteCLIP 在 zero-shot、线性探针、k-NN、少样本以及图像-文本检索任务上的表现。
- 支持多种骨干网络规模(ResNet-50、ViT-Base-32、ViT-Large-14),以展示模型与数据规模的影响。
- 提供一个新的 RemoteCount 基准,用于遥感中的目标计数。
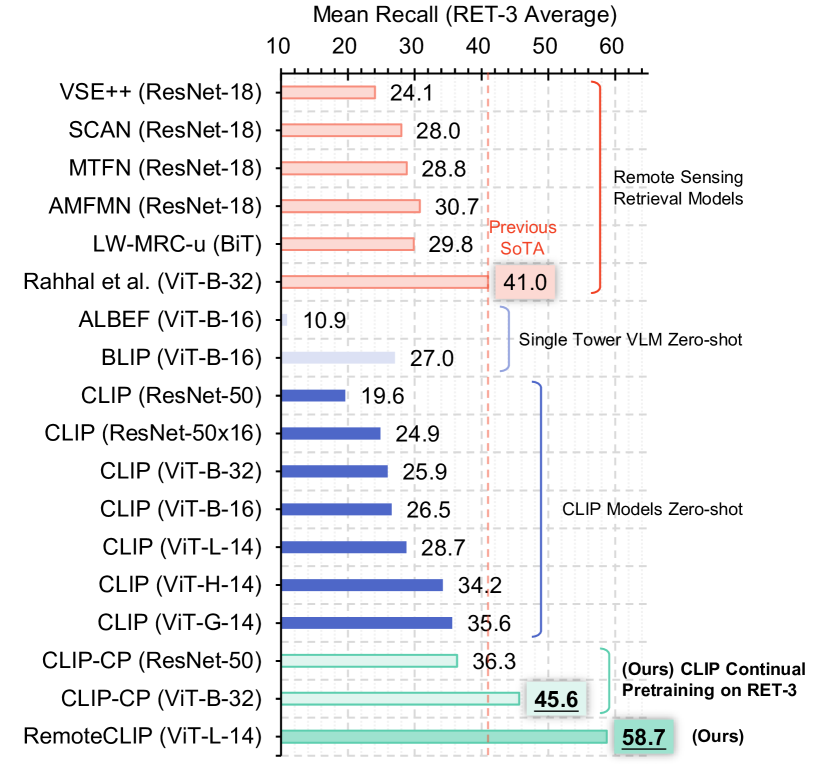
实验结果
研究问题
- RQ1在大规模统一的遥感图像-标题数据上训练的视觉-语言基础模型,是否能在多样化的下游任务中超越领域特定基线?
- RQ2通过注释统一(B2C 和 M2B)的数据扩展,是否能实现更强的语义对齐和更好的零-shot/少样本性能?
- RQ3不同的骨干规模如何影响 RemoteCLIP 在遥感中的分类和检索任务的性能?
- RQ4在遥感领域对同领域数据进行持续预训练对基于 CLIP 的模型是否有益?
- RQ5单一模型是否能够在多种遥感模态(卫星和无人机)和多种任务(计数、检索、分类)上达到出色表现?
主要发现
- RemoteCLIP 的零-shot 分类性能在 12 个下游数据集上,平均准确率最高比 CLIP 基线提升至 6.39%。
- 持续预训练(CLIP-CP)显著提升检索基准,在 RSITMD、RSICD 和 UCM 上创造了新的最先进水平。
- 数据扩展到 RET-3/SEG-4/DET-10+ 数据集的 12 倍,相比较小尺度的持续预训练带来显著收益。
- RemoteCLIP 在 16 个遥感数据集上,跨越从 ResNet-50 到 ViT-Large-14 的任务和模型规模,表现优于基线基础模型。
- RSITMD 和 RSICD 的提升分别为平均召回率提高 9.14% 和 8.92%,相对于相关基线。
- 该模型在零-shot、线性探针、k-NN、少样本分类以及图像-文本检索等任务上展现出多样性能力。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。