[论文解读] RePLan: Robotic Replanning with Perception and Language Models
RePLan 使用分层基于大语言模型的规划器、一个视觉语言模型感知器,以及一个验证器,以实现对长期机器人任务的实时重新规划和奖励生成,在多个环境中展示出强大性能。
Advancements in large language models (LLMs) have demonstrated their potential in facilitating high-level reasoning, logical reasoning and robotics planning. Recently, LLMs have also been able to generate reward functions for low-level robot actions, effectively bridging the interface between high-level planning and low-level robot control. However, the challenge remains that even with syntactically correct plans, robots can still fail to achieve their intended goals due to imperfect plans or unexpected environmental issues. To overcome this, Vision Language Models (VLMs) have shown remarkable success in tasks such as visual question answering. Leveraging the capabilities of VLMs, we present a novel framework called Robotic Replanning with Perception and Language Models (RePLan) that enables online replanning capabilities for long-horizon tasks. This framework utilizes the physical grounding provided by a VLM's understanding of the world's state to adapt robot actions when the initial plan fails to achieve the desired goal. We developed a Reasoning and Control (RC) benchmark with eight long-horizon tasks to test our approach. We find that RePLan enables a robot to successfully adapt to unforeseen obstacles while accomplishing open-ended, long-horizon goals, where baseline models cannot, and can be readily applied to real robots. Find more information at https://replan-lm.github.io/replan.github.io/
研究动机与目标
- 在尽量减少人工干预的情况下,激励并实现自治、长期机器人任务执行。
- 通过语言模型和视觉定位,将高层规划与低层控制桥接起来。
- 结合感知反馈和验证,减少计划失败和幻觉(错误推断)。
- 展示开放式、多步任务求解,采用无强化学习的奖励生成流程。
提出的方法
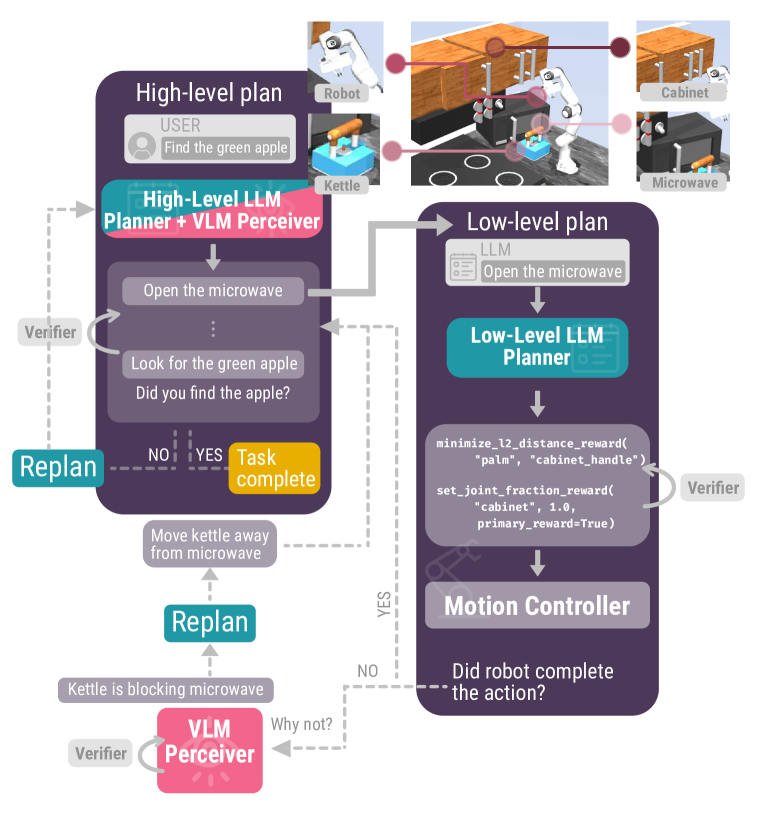
- 高级别的LLM规划器从用户目标生成抽象子任务。
- VLM感知器提供有据可查的状态观测和对象状态反馈。
- 低级别的LLM规划器将高级子任务转换为低级奖励函数。
- 运动控制器(MuJoCo MPC)使用生成的奖励执行动作。
- LLM验证器检查并纠正规划器输出,确保行动与目标一致。
实验结果
研究问题
- RQ1一个使用LLM和VLM的多层规划系统是否能够在实时重新规划下执行长期、开放式的机器人任务?
- RQ2与基线的基于LLM或非感知化的方法相比,整合感知定位与验证是否能提高任务成功率和鲁棒性?
- RQ3基于LLM的奖励生成流程在基于MPC的机器人操作中的控制效果如何?
- RQ4移除模块(Verifier、Perceiver、Replan)对长期任务执行有何影响?
主要发现
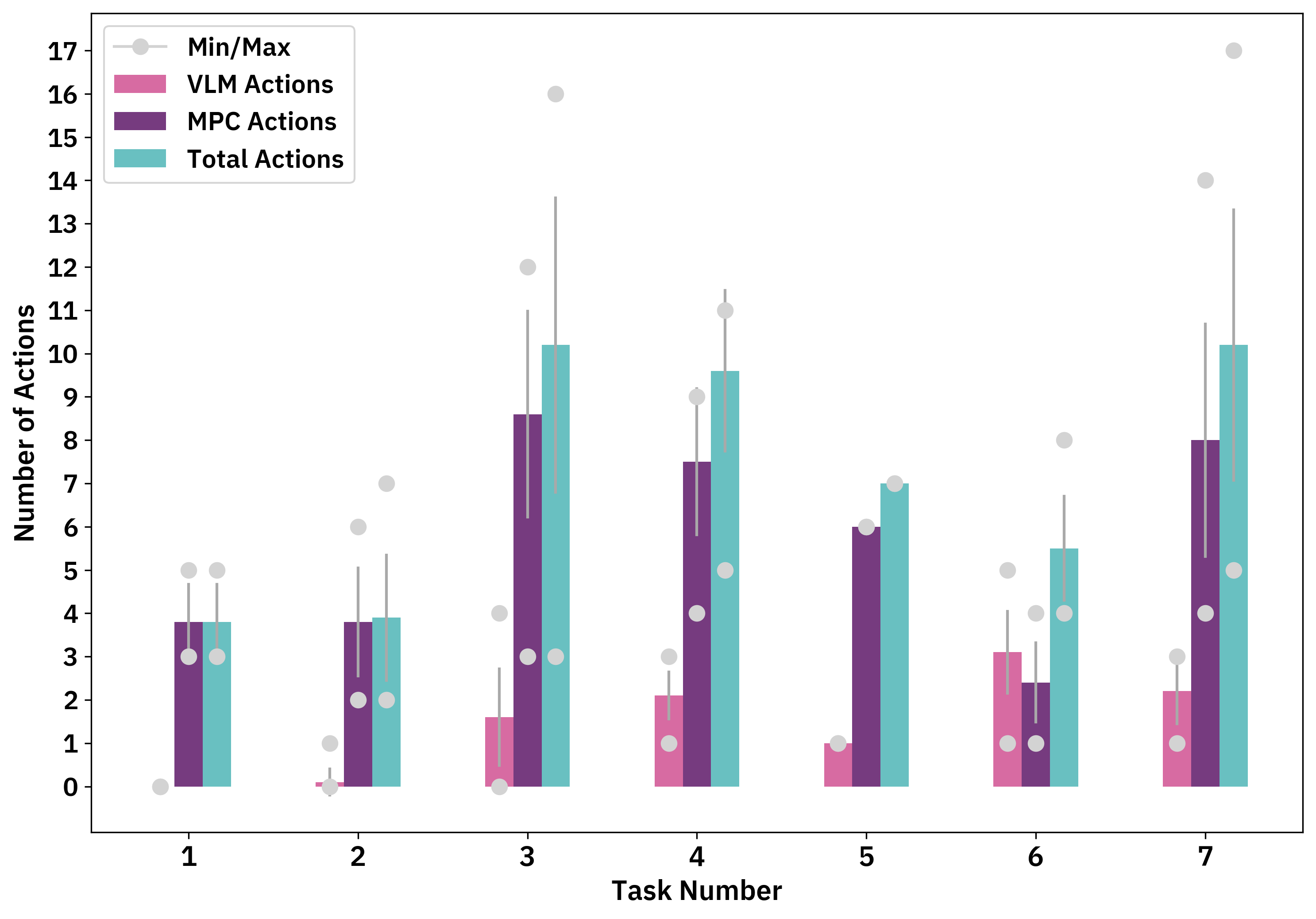
- RePLan在七个任务中的平均成功率为88.6%,显著高于基线。
- 与 Language to Rewards 相比,RePLan 在整体任务完成方面提升了3.6×。
- 消融实验显示在移除 Verifier、Perceiver 或 Replan 模块时性能显著下降,移除 Perceiver 或 Replan 时下降最大。
- 任务级别的性能存在差异(例如,任务3是最困难的),反映出障碍以及正确的奖励优先级等挑战。
- 系统展示开放式问题解决能力,包括在失败后重新规划及处理未见过的障碍。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。