[论文解读] RepViT: Revisiting Mobile CNN From ViT Perspective
RepViT 表明,经过以 ViT 启发的架构设计现代化的纯轻量级 CNN,在移动设备上的精度与延迟方面可超越轻量级 ViT,在 ImageNet 上的 top-1 超过 80%,且在 iPhone 12 上 M1 规模模型实现 1 ms 延迟。
Recently, lightweight Vision Transformers (ViTs) demonstrate superior performance and lower latency, compared with lightweight Convolutional Neural Networks (CNNs), on resource-constrained mobile devices. Researchers have discovered many structural connections between lightweight ViTs and lightweight CNNs. However, the notable architectural disparities in the block structure, macro, and micro designs between them have not been adequately examined. In this study, we revisit the efficient design of lightweight CNNs from ViT perspective and emphasize their promising prospect for mobile devices. Specifically, we incrementally enhance the mobile-friendliness of a standard lightweight CNN, \ie, MobileNetV3, by integrating the efficient architectural designs of lightweight ViTs. This ends up with a new family of pure lightweight CNNs, namely RepViT. Extensive experiments show that RepViT outperforms existing state-of-the-art lightweight ViTs and exhibits favorable latency in various vision tasks. Notably, on ImageNet, RepViT achieves over 80\% top-1 accuracy with 1.0 ms latency on an iPhone 12, which is the first time for a lightweight model, to the best of our knowledge. Besides, when RepViT meets SAM, our RepViT-SAM can achieve nearly 10$ imes$ faster inference than the advanced MobileSAM. Codes and models are available at \url{https://github.com/THU-MIG/RepViT}.
研究动机与目标
- 评估当前轻量级 CNN 相对于轻量级 ViT 在移动设备上的局限性。
- 探索 ViT 启发的架构设计,将 MobileNetV3-L 现代化为纯 CNN 骨干。
- 证明 RepViT 在 ImageNet 上具有更优的延迟-精度,并能良好迁移到下游任务。
提出的方法
- 以 MobileNetV3-L 为起点,逐步融入 ViT 启发的设计原则。
- 通过结构重新参数化,将 token mixer 和 channel mixer 分离,引入 RepViT 模块。
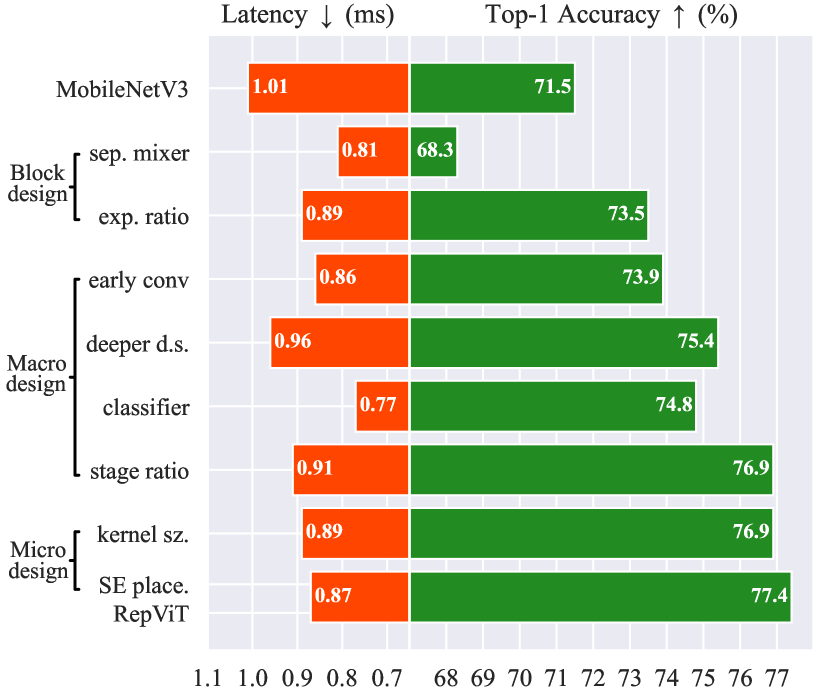
- 应用宏观架构调整:带早期卷积的干预阶段、加深下采样、简化分类器,以及优化阶段比。
- 进行微观架构细化:将卷核大小归一为 3x3,并优化跨模块的 SE 放置。
- 在 ImageNet-1K 上训练并评估所有模型;在 iPhone 12 上使用 Core ML Tools 测量设备端延迟;在 COCO 和 ADE20K 上验证。
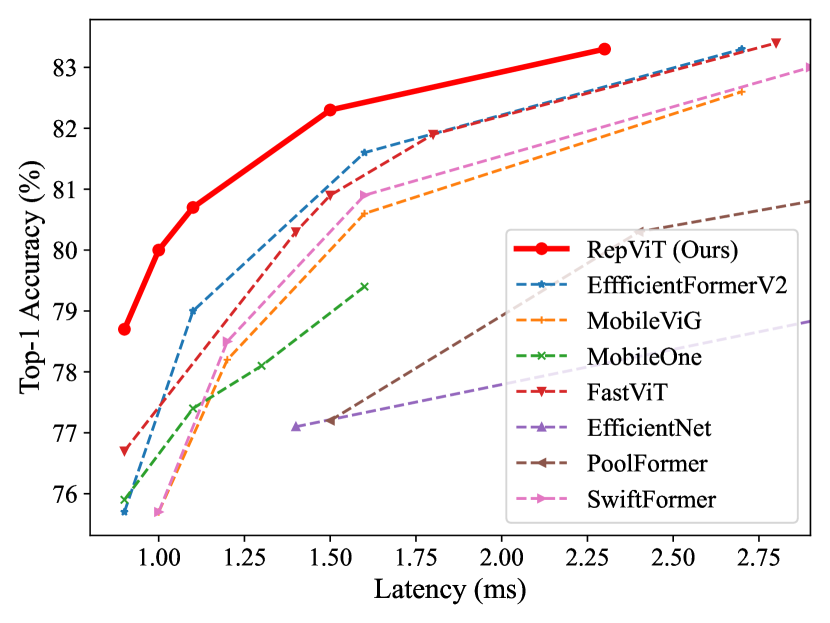
实验结果
研究问题
- RQ1来自轻量级 ViT 的架构选择能否提升纯 CNN 在移动设备上的性能与延迟?
- RQ2哪些宏观和微观设计调整最能在边缘设备上缩小 CNN 与 ViT 的差距?
- RQ3与最先进的轻量级 ViT 和 CNN 相比,RepViT 在 ImageNet 的表现及对下游任务的迁移能力如何?
主要发现
- 在不同模型规模下,RepViT 在延迟和准确率方面领先于现有的最先进轻量级 ViT 和 CNN。
- RepViT-M0.9 至 RepViT-M2.3 在 ImageNet 上取得强劲结果,并在 iPhone 12 上实现显著更低的设备端延迟(例如,小型变体为 1 ms,较大变体为 2.3 ms)。
- RepViT-M1.0 在 iPhone 12 上以 1 ms 延迟达到超过 80% 的 top-1 精度;RepViT-M2.3 达到 83.7% 的准确率,延迟 2.3 ms。
- 下游任务(COCO 目标检测/分割与 ADE20K 语义分割)显示 RepViT 骨干在较低延迟下实现有竞争力的 AP 与 mIoU。
- 结构重参数化与跨块 SE 放置持续改善准确率-延迟权衡。
- RepViT 证明,当整合 ViT 启发的架构原则时,纯轻量级 CNN 能在移动设备上超越轻量级 ViT。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。