[论文解读] Researchy Questions: A Dataset of Multi-Perspective, Decompositional Questions for LLM Web Agents
这篇论文引入 Researchy Questions,一个来自真实搜索日志的大规模非事实性、分解性、多观点问题数据集,用于研究大模型网页代理在处理不清晰信息需求时的表现,包含 96k 个问题及相关的分解计划和点击证据。
Existing question answering (QA) datasets are no longer challenging to most powerful Large Language Models (LLMs). Traditional QA benchmarks like TriviaQA, NaturalQuestions, ELI5 and HotpotQA mainly study ``known unknowns'' with clear indications of both what information is missing, and how to find it to answer the question. Hence, good performance on these benchmarks provides a false sense of security. A yet unmet need of the NLP community is a bank of non-factoid, multi-perspective questions involving a great deal of unclear information needs, i.e. ``unknown uknowns''. We claim we can find such questions in search engine logs, which is surprising because most question-intent queries are indeed factoid. We present Researchy Questions, a dataset of search engine queries tediously filtered to be non-factoid, ``decompositional'' and multi-perspective. We show that users spend a lot of ``effort'' on these questions in terms of signals like clicks and session length, and that they are also challenging for GPT-4. We also show that ``slow thinking'' answering techniques, like decomposition into sub-questions shows benefit over answering directly. We release $\sim$ 100k Researchy Questions, along with the Clueweb22 URLs that were clicked.
研究动机与目标
- 激发对复杂的、非事实性问题的需求,这些问题揭示现实世界用户信息需求中的未知因素。
- 描述将搜索日志查询挖掘、筛选和去重为分解型问答数据集的构建流程。
- 提供分层次的分解和证据信号(点击的 URL)以支撑并评估 LLM 代理的行为。
- 提供基线评估,展示分解式回答的好处以及对 Researchy Questions 的用户搜索行为洞见。
提出的方法
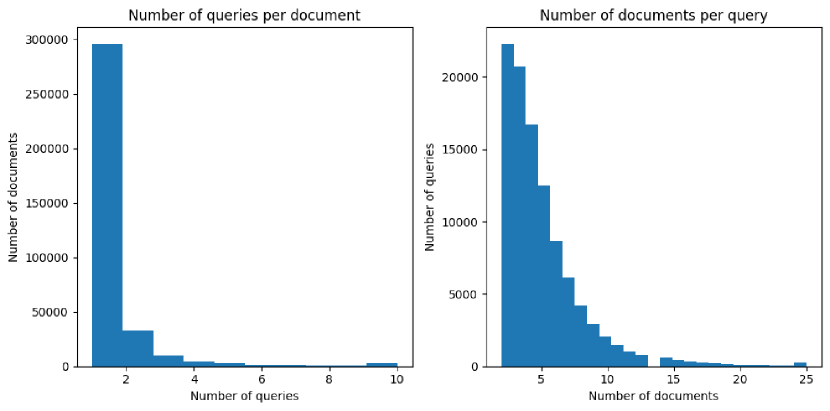
- 挖掘现实世界的英文搜索日志,收集至少出现 50 次且有多个点击 URL 的候选问题。
- 按阶段筛选,以使用分类器和 GPT-4 标注来提取适合分解式回答的非事实性、开放领域问题。
- 使用基于 ANCE 的嵌入和聚类进行查询意图的聚合去重,生成组的代表性头部。
- 应用最终基于 GPT-4 的质量检查,筛除模糊、不完整、假设性或不安全的问题,产出 96k 个问题。
- 为每个问题提供 2 级分层分解,并发布相应的 ClueWeb22 点击 URL 作为证据信号。

实验结果
研究问题
- RQ1What are Researchy Questions, and how do they differ from traditional factoid QA benchmarks?
- RQ2Can non-factoid, decompositional questions mined from search logs effectively reveal unknown unknowns for LLM web agents?
- RQ3Do hierarchical decompositions improve retrieval and synthesis for complex, multi-document queries compared to direct answering?
- RQ4What behavioral signals (e.g., clicks, session length) indicate greater effort and complexity in Researchy Questions?
- RQ5How do decompositional answering techniques compare to direct answering on long-form, multi-perspective questions?
主要发现
- Researchy Questions are non-factoid, decompositional, and multi-perspective, requiring substantial research effort beyond a paragraph answer.
- Users spend more time and clicks on Researchy Questions, indicating higher information-seeking effort and diverse evidence needs.
- GPT-4-based decomposition approaches (especially factored decomposition) outperform direct closed-book answering on long-form, multi-faceted questions.
- Decompositional techniques yield accuracy and quality gains on long-form questions, with notable improvements for datasets like Wikihow and Researchy Questions.
- Approximately 96k questions are released, each with a 2-level hierarchical plan and a vector-based deduplication head, plus the associated ClueWeb22 clicked URLs.
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。