[论文解读] Rethinking BiSeNet For Real-time Semantic Segmentation
本文提出 STDC-Seg,采用 Short-Term Dense Concatenate 骨干网络和 Detail Guidance 解码器,能够在不增加推理成本的情况下实现快速、准确的实时语义分割。
BiSeNet has been proved to be a popular two-stream network for real-time segmentation. However, its principle of adding an extra path to encode spatial information is time-consuming, and the backbones borrowed from pretrained tasks, e.g., image classification, may be inefficient for image segmentation due to the deficiency of task-specific design. To handle these problems, we propose a novel and efficient structure named Short-Term Dense Concatenate network (STDC network) by removing structure redundancy. Specifically, we gradually reduce the dimension of feature maps and use the aggregation of them for image representation, which forms the basic module of STDC network. In the decoder, we propose a Detail Aggregation module by integrating the learning of spatial information into low-level layers in single-stream manner. Finally, the low-level features and deep features are fused to predict the final segmentation results. Extensive experiments on Cityscapes and CamVid dataset demonstrate the effectiveness of our method by achieving promising trade-off between segmentation accuracy and inference speed. On Cityscapes, we achieve 71.9% mIoU on the test set with a speed of 250.4 FPS on NVIDIA GTX 1080Ti, which is 45.2% faster than the latest methods, and achieve 76.8% mIoU with 97.0 FPS while inferring on higher resolution images.
研究动机与目标
- 设计一个高效的骨干网络(STDC 模块),在更少参数和计算量的情况下提供可扩展的感受野。
- 通过 Detail Guidance 将空间细节学习整合到低层特征中,消除额外空间路径的需求。
- 将高级语义特征与经过引导的低级细节融合,以改善边界保留。
- 通过端到端单流架构,在实时分割基准(Cityscapes、CamVid)上实现强劲的速度–精度权衡。
提出的方法
- 引入 STDC 模块,将来自若干块的多尺度特征图通过逐步减小的卷积核进行串联,以获得可扩展的感受野并降低 FLOPs。
- 通过对中间图进行下采样并统一分辨率后,利用拼接对 STDC 块输出进行下采样融合。
- 在解码器中,通过 Detail Aggregation 模块应用 Detail Guidance,该模块通过基于拉普拉斯的过程生成二值细节真值标签,并通过 Detail Head 指导低层特征且不增加推理成本。
- 结合分割损失和细节损失进行训练(L_detail = L_Dice + L_BCE),以引导低层特征朝着空间细节;推理阶段仅使用分割路径。
- 使用受 BiSeNet 启发的上下文路径来实现多尺度上下文,并通过 Feature Fusion 模块与解码器融合。
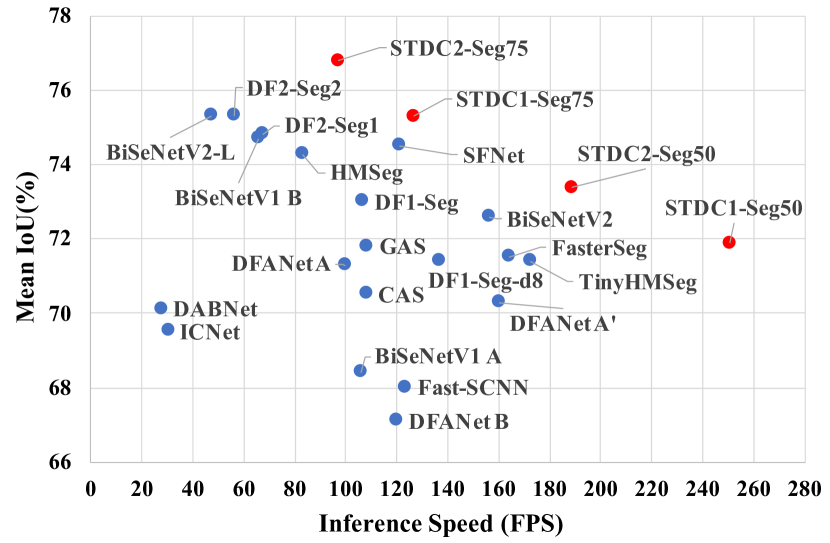
实验结果
研究问题
- RQ1提议的 STDC 骨干网络是否能够在实时分割中,相比轻量级骨干网络以显著更高的速度达到具有竞争力的分割精度?
- RQ2Detail Guidance 模块在不增加推理时间的情况下,是否改善边界和小物体的勾勒?
- RQ3就 mIoU 和 FPS 而言,STDC-Seg 与 Cityscapes 和 CamVid 上的最新实时分割方法相比如何?
- RQ4STDC 块数量对精度和速度的影响是什么?
- RQ5单流解码器搭配 Detail Guidance 是否足以替代 BiSeNet 风格的双通路结构?
主要发现
- STDC2-Seg50 在 Cityscapes 512x1024 输入下达到 73.4% mIoU,速度 188.6 FPS。
- STDC1-Seg50 在 Cityscapes 512x1024 输入下达到 71.9% mIoU,速度 250.4 FPS。
- STDC2-Seg75 在 Cityscapes 768x1536 输入下达到 76.8% mIoU,速度 97.0 FPS。
- 在 Cityscapes 验证集上,STDC2-Seg75 实现 77.0% mIoU,97.0 FPS(768x1536 输入)。
- STDC1-Seg 在 CamVid (720x960) 上达到 73.0% mIoU,197.6 FPS。
- Detail Guidance 提升边界和小目标勾勒而不增加推理成本,在单位计算量的精度方面超过基于 Spatial Path 的配置。
![Figure 2: Illustration of architectures of BiSeNet [ 28 ] and our proposed approach. (a) presents Bilateral Segmentation Network (BiSeNet [ 28 ] ), which use an extra Spatial Path to encode spatial information. (b) demonstrates our proposed method, which use a Detail Guidance module to encode spatia](https://ar5iv.labs.arxiv.org/html/2104.13188/assets/figures/architecture-comparison.png)
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。