[论文解读] Rethinking Large Language Models in Mental Health Applications
这篇论文批评生成式大型语言模型在心理健康任务中的使用,强调不稳定性、潜在的幻觉风险,以及可解释性与解释性的区别,同时倡导以人为本、可审计且本质可解释的方法。
Large Language Models (LLMs) have become valuable assets in mental health, showing promise in both classification tasks and counseling applications. This paper offers a perspective on using LLMs in mental health applications. It discusses the instability of generative models for prediction and the potential for generating hallucinatory outputs, underscoring the need for ongoing audits and evaluations to maintain their reliability and dependability. The paper also distinguishes between the often interchangeable terms ``explainability'' and ``interpretability'', advocating for developing inherently interpretable methods instead of relying on potentially hallucinated self-explanations generated by LLMs. Despite the advancements in LLMs, human counselors' empathetic understanding, nuanced interpretation, and contextual awareness remain irreplaceable in the sensitive and complex realm of mental health counseling. The use of LLMs should be approached with a judicious and considerate mindset, viewing them as tools that complement human expertise rather than seeking to replace it.
研究动机与目标
- 评估生成式LLMs在心理健康应用中的现状与挑战。
- 强调基于生成的预测与解释中的不稳定性与幻觉风险。
- 澄清心理健康AI中可解释性与解释性之间的差异。
- 主张以人为本地使用LLMs作为工具来辅助而非取代临床医生。
提出的方法
- 回顾基于LLM的心理健康应用的最新进展,包括早期预测、解释与咨询。
- 讨论将“生成即预测”和元优化作为潜在解释框架的不稳定性。
- 评估可解释性与解释性及LLM生成解释的可信度。
- 提出在心理健康情境下部署LLMs的审计、安全与伦理指南。
- 综合对咨询聊天机器人和以人为本设计的影响。
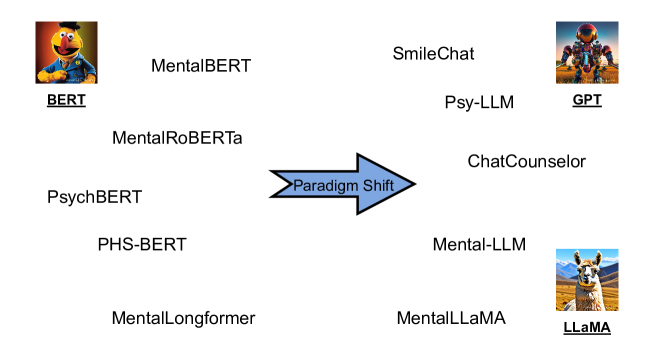
实验结果
研究问题
- RQ1在心理健康预测和咨询中使用生成式LLMs的主要局限性和风险是什么?
- RQ2在应用于心理健康的LLMs环境中,可解释性与解释性有何区别,以及会产生哪些可信度问题?
- RQ3在心理健康Settings中负责任地部署LLMs需要哪些保障、审计和伦理考虑?
主要发现
- LLMs在基于生成的预测中随着提示的微小变化表现出不稳定性。
- LLM生成的解释可能不真实且不能保证真正的可解释性。
- 在心理健康分类任务中,专业的、面向任务的判别模型在性能上可以胜过基于生成的方法。
- 一些LLMs明确限制高风险使用,反映出伦理和实际关切。
- 人类提供的同理理解和情境敏感性是LLMs目前无法在心理健康咨询中取代的。
- 为了负责任的使用,进行可靠性、偏见和输入敏感性的审计至关重要。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。