[论文解读] Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers
提出 SETR,一种纯Transformer编码器,将图像视为patch序列进行语义分割,在ADE20K和Pascal Context上达到最先进水平,并在Cityscapes上表现具有竞争力。
Most recent semantic segmentation methods adopt a fully-convolutional network (FCN) with an encoder-decoder architecture. The encoder progressively reduces the spatial resolution and learns more abstract/semantic visual concepts with larger receptive fields. Since context modeling is critical for segmentation, the latest efforts have been focused on increasing the receptive field, through either dilated/atrous convolutions or inserting attention modules. However, the encoder-decoder based FCN architecture remains unchanged. In this paper, we aim to provide an alternative perspective by treating semantic segmentation as a sequence-to-sequence prediction task. Specifically, we deploy a pure transformer (ie, without convolution and resolution reduction) to encode an image as a sequence of patches. With the global context modeled in every layer of the transformer, this encoder can be combined with a simple decoder to provide a powerful segmentation model, termed SEgmentation TRansformer (SETR). Extensive experiments show that SETR achieves new state of the art on ADE20K (50.28% mIoU), Pascal Context (55.83% mIoU) and competitive results on Cityscapes. Particularly, we achieve the first position in the highly competitive ADE20K test server leaderboard on the day of submission.
研究动机与目标
- 重新审视超越编码器-解码器 FCN 架构的语义分割。
- 引入一个在空间分辨率上不进行下采样的纯Transformer编码器。
- 探索解码器设计,以从Transformer特征恢复全分辨率分割。
- 证明跨图像patch的全局自注意力可生成更优的特征表示。
提出的方法
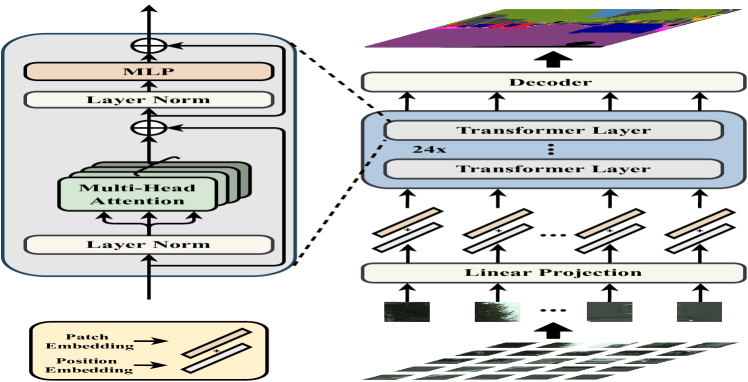
- 将图像分割为固定大小的patch并将它们线性嵌入成1D序列。
- 使用具全局自注意力的纯Transformer编码器来学习patch级特征。
- 通过可学习的patch位置嵌入加入空间信息。
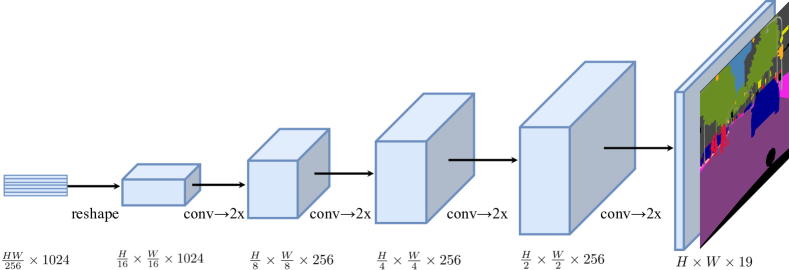
- 尝试三种解码器设计:朴素上采样、渐进上采样(PUP)和多层级特征聚合(MLA)。
- 在适用的情况下用 ViT/DeiT 预训练Transformer骨架,并在中间Transformer层整合辅助损失。
实验结果
研究问题
- RQ1基于图像patch的纯Transformer编码器能否取代卷积编码器用于语义分割?
- RQ2在使用Transformer编码器时,不同解码器设计对像素级分割有何影响?
- RQ3预训练策略(ViT/DeiT)对SETR在标准分割基准上的性能影响如何?
主要发现
- SETR在ADE20K上实现了最先进的性能(50.28% mIoU,使用MS推断)和Pascal Context上(55.83% mIoU,使用MS推断)。
- SETR在Cityscapes上显示出竞争力,SETR-PUP超越了许多基于FCN和带注意力的基线。
- 对Transformer编码器(ViT/DeiT)的预训练显著提升性能,优于随机初始化的变体。
- 三种解码器设计显示出不同的权衡,渐进上采样(SETR-PUP)通常在准确性和复杂度之间提供最佳平衡。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。