[论文解读] Rethinking the Role of Token Retrieval in Multi-Vector Retrieval
XTR 将多向量检索中的令牌检索重新定位为仅使用已检索的令牌直接对文档进行评分,从而消除聚集阶段、显著降低评分成本,同时在 BEIR/LoTTE 上达到最先进水平并在 MS MARCO 上表现出色。
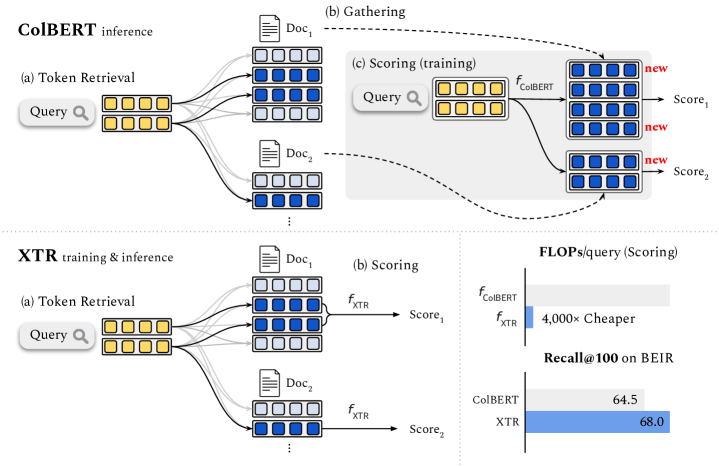
Multi-vector retrieval models such as ColBERT [Khattab and Zaharia, 2020] allow token-level interactions between queries and documents, and hence achieve state of the art on many information retrieval benchmarks. However, their non-linear scoring function cannot be scaled to millions of documents, necessitating a three-stage process for inference: retrieving initial candidates via token retrieval, accessing all token vectors, and scoring the initial candidate documents. The non-linear scoring function is applied over all token vectors of each candidate document, making the inference process complicated and slow. In this paper, we aim to simplify the multi-vector retrieval by rethinking the role of token retrieval. We present XTR, ConteXtualized Token Retriever, which introduces a simple, yet novel, objective function that encourages the model to retrieve the most important document tokens first. The improvement to token retrieval allows XTR to rank candidates only using the retrieved tokens rather than all tokens in the document, and enables a newly designed scoring stage that is two-to-three orders of magnitude cheaper than that of ColBERT. On the popular BEIR benchmark, XTR advances the state-of-the-art by 2.8 nDCG@10 without any distillation. Detailed analysis confirms our decision to revisit the token retrieval stage, as XTR demonstrates much better recall of the token retrieval stage compared to ColBERT.
研究动机与目标
- Motivate simplification of the traditional three-stage multi-vector retrieval pipeline (token retrieval, gathering, scoring).
- Propose a training objective that encourages retrieval of salient document tokens first.
- Develop a scoring mechanism that operates on retrieved tokens and supports missing-token imputation to approximate full-document scores.
- Demonstrate state-of-the-art zero-shot IR performance on BEIR and LoTTE without distillation or hard negative mining.
- Show substantial reduction in scoring computation compared to ColBERT while maintaining strong in-domain performance.
提出的方法
- Introduce XTR, a contextualized token retriever with a novel in-batch alignment strategy where A_ij=1 only if document token d_j is retrieved within top-k_train for query token i among in-batch tokens.
- Define f_XTR(Q,D) = (1/Z) sum_i max_j A_ij q_i^T d_j, with Z counting query tokens that retrieve at least one document token (normalizer).
- During inference, score documents using only the retrieved tokens, eliminating the gathering stage; reuse retrieval scores for efficiency.
- Introduce missing similarity imputation in f_XTR' to estimate scores for non-retrieved tokens, providing an upper bound based on the top-k' retrieved scores.
- Train with standard cross-entropy loss but with the XTR scoring function, ensuring tokens from relevant documents are retrieved more often.
- Provide an upper-bound imputation m_i for missing similarities using the last retrieved token score to tighten scoring.
实验结果
研究问题
- RQ1Can token retrieval alone yield competitive or superior document ranking in multi-vector retrieval?
- RQ2How should token retrieval be trained to prioritize salient document tokens for effective downstream scoring?
- RQ3Can the scoring stage be made order-of-magnitude cheaper by relying only on retrieved tokens and imputation for missing similarities?
- RQ4Do zero-shot benchmarks (BEIR/LoTTE) benefit from the proposed training objective and missing similarity imputation?
- RQ5What is the impact of XTR on multilingual retrieval tasks without distillation or additional pre-training?
主要发现
- XTR achieves state-of-the-art performance on BEIR in zero-shot settings without distillation or hard negative mining.
- XTR significantly reduces scoring computation (up to two-to-three orders of magnitude cheaper than ColBERT) by relying on retrieved tokens and removing the gathering stage.
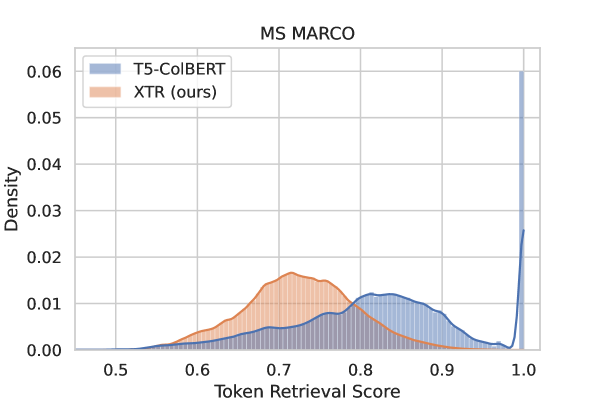
- Training with the in-batch token retrieval objective substantially improves the recall of gold tokens in the top-k retrieved tokens.
- XTR demonstrates better contextual token retrieval compared to ColBERT, improving gold token retrieval probability and contextual matching.
- Multilingual XTR (mXTR) outperforms contrastive pre-training baselines (e.g., mContriever) on MIRACL, showcasing strong cross-language retrieval without extra pre-training.
- Imputation-based scoring (XTR') can achieve competitive results while further reducing computation, with recall improving as k' grows.
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。