[论文解读] Reverse Engineering Self-Supervised Learning
本论文通过实证分析 SSL 表征,显示 SSL 引入语义聚类和由正则化驱动的信息压缩,并且在训练过程中未使用标签时,语义对齐在不同层次和层级上得到改善。
Self-supervised learning (SSL) is a powerful tool in machine learning, but understanding the learned representations and their underlying mechanisms remains a challenge. This paper presents an in-depth empirical analysis of SSL-trained representations, encompassing diverse models, architectures, and hyperparameters. Our study reveals an intriguing aspect of the SSL training process: it inherently facilitates the clustering of samples with respect to semantic labels, which is surprisingly driven by the SSL objective's regularization term. This clustering process not only enhances downstream classification but also compresses the data information. Furthermore, we establish that SSL-trained representations align more closely with semantic classes rather than random classes. Remarkably, we show that learned representations align with semantic classes across various hierarchical levels, and this alignment increases during training and when moving deeper into the network. Our findings provide valuable insights into SSL's representation learning mechanisms and their impact on performance across different sets of classes.
研究动机与目标
- 研究 SSL 训练得到的表征在样本增强与语义类别方面的聚类情况。
- 探索正则化与不变性在驱动聚类中的作用。
- 评估 SSL 表征在跨层级的语义类别对齐程度。
- 考察训练过程中跨网络层的聚类与语义对齐如何演化。
提出的方法
- 在 CIFAR-100 上使用标准数据增强训练 SSL 模型(如 VICReg)。 通过最近邻类中心(NCC)准确率和类别方差度量(CDNV)衡量聚类。 分析训练轮次中样本级与语义类别聚类动力学。 将 SSL 损失分解为不变性和正则化两部分,以评估其影响。 在训练过程中估计输入与嵌入之间的互信息(MINE)。 评估线性探针性能以及跨层与目标的层次聚类(样本、100 个类别、20 个超类)。
- 使用 RES-L-H(ResNet 变体)主干网络,配备两层 MLP 投影头用于 VICReg 实验。
- 将 SSL 聚类与有监督聚类在有无数据增强情境下进行对比,以将结果放在背景中分析。
- 通过创建具有不同语义意义的目标标签来研究目标随机性并跟踪学习过程。
- 检查中间层以确定在深度上如何捕捉到层次化的语义目标。

实验结果
研究问题
- RQ1除了增强外,SSL 训练得到的表征是否也会对语义类别进行聚类?
- RQ2在 SSL 中,正则化项在促进语义聚类和信息压缩方面起到何种作用?
- RQ3随着训练进展和网络深度增加,向语义目标的对齐如何演化?
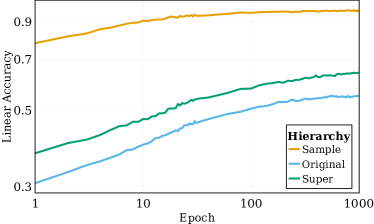
- RQ4SSL 表征是否能够在不同层级(样本、原始类别、超类)学习并反映层次化的类别结构?
- RQ5目标的随机性如何影响 SSL 表征与语义结构对齐的能力?
主要发现
- SSL 训练在对增强样本进行聚类方面表现出强烈的聚类趋势,且在后期训练阶段对语义类别的聚类越来越明显。
- 正则化而非不变性,主要驱动语义聚类的改进及下游线性准确性的提升,不变性在早期趋于饱和。
- 在层级上,表征与语义类别呈高度对齐,即使在 SSL 训练阶段未使用标签信息。
- 向更深层的层级聚类语义类别有提升,且更深的层更好地捕捉高层次结构(超类)而非原始类别。
- 输入与嵌入之间的互信息在训练过程中下降,指示隐式信息压缩。
- SSL 模型在样本层级呈现类似神经群集-质心结构,并且存在持续的语义聚类,随训练而增强。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。