[论文解读] Revisiting Feature Prediction for Learning Visual Representations from Video
本文提出 V-JEPA,一系列仅使用特征预测目标在 2M 条视频上进行预训练的视觉模型,在冻结主干网络且预训练时间更短的情况下,获得强劲的运动表示和外观表示。
This paper explores feature prediction as a stand-alone objective for unsupervised learning from video and introduces V-JEPA, a collection of vision models trained solely using a feature prediction objective, without the use of pretrained image encoders, text, negative examples, reconstruction, or other sources of supervision. The models are trained on 2 million videos collected from public datasets and are evaluated on downstream image and video tasks. Our results show that learning by predicting video features leads to versatile visual representations that perform well on both motion and appearance-based tasks, without adaption of the model's parameters; e.g., using a frozen backbone. Our largest model, a ViT-H/16 trained only on videos, obtains 81.9% on Kinetics-400, 72.2% on Something-Something-v2, and 77.9% on ImageNet1K.
研究动机与目标
- 推动从视频中进行无监督视觉表征学习,使用独立的特征预测目标。
- 开发基于 JEPA 的框架,在没有预训练编码器或像素重建的情况下,从源表示预测目标表示。
- 评估特征预测预训练在冻结和微调设置下向下游图像和视频任务的迁移效果。
- 分析影响基于视频的表征学习性能的设计选择(掩蔽、数据分布、池化)。
提出的方法
- 采用联合嵌入预测架构(JEPA),通过在视频输入中从 x 预测 y 来学习。
- 使用掩蔽特征预测任务,其中 x 是视频的掩蔽子集,y 是补充目标,采用 L1 损失并进行 stop-gradient/EMA 抑制塌陷。
- 将 x 和 y 表征为基于 ViT 的编码器,以及在带可学习掩码标记的掩蔽标记序列上运行的轻量级预测器。
- 采用多块掩蔽策略来掩蔽大规模连续的时空区域,创造具有挑战性的预测任务。
- 通过注意力探针、自适应池化以及端到端微调进行评估,以评估冻结和微调下的性能。
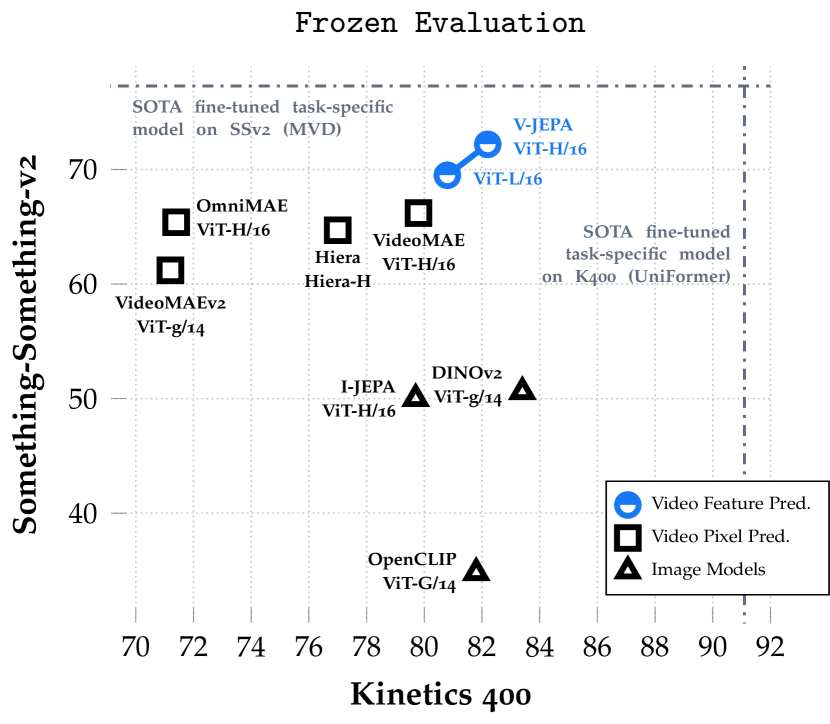
实验结果
研究问题
- RQ1作为独立目标的特征预测在从视频进行无监督视觉表征学习中的有效性如何?
- RQ2基于视频的特征预测是否能在不改变模型权重的情况下,为运动型和外观型下游任务产生良好迁移的表征?
- RQ3哪些设计选择(掩蔽策略、数据混合、池化)对从视频学习得到的表征质量影响最大?
主要发现
- 使用 V-JEPA 的特征预测产生多功能表征,在冻结主干的情况下在运动型任务(Something-Something-v2)和外观型任务(Kinetics-400)上表现良好。
- 在冻结评估下,特征预测预训练优于像素预测基线;在微调下具有竞争力,且预训练时间更短。
- 通过跨注意力的自适应池化显著优于简单平均池化的下游表现(特别是在 K400 和 SSv2 上)。
- 增加预训练数据量可提升平均下游表现,通过针对任务的数据混合(针对任务定制的数据混合,VideoMix2M 通常提供最佳平均值)实现最优结果。
- V-JEPA 展现出标注效率,在较少标注数据条件下与像素预测基线相比存在更大差距。
- 与像素预测视频模型相比,V-JEPA 在需要更少的预训练样本和更少的计算量的情况下实现竞争或更优的性能。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。