[论文解读] Revisiting the Plastic Surgery Hypothesis via Large Language Models
本文提出 FitRepair,一种基于 LLM 的自动程序修复(APR)方法,通过微调与提示利用可塑性假设,在 Defects4j 1.2 和 2.0 上实现了最先进的修复结果。
Automated Program Repair (APR) aspires to automatically generate patches for an input buggy program. Traditional APR tools typically focus on specific bug types and fixes through the use of templates, heuristics, and formal specifications. However, these techniques are limited in terms of the bug types and patch variety they can produce. As such, researchers have designed various learning-based APR tools with recent work focused on directly using Large Language Models (LLMs) for APR. While LLM-based APR tools are able to achieve state-of-the-art performance on many repair datasets, the LLMs used for direct repair are not fully aware of the project-specific information such as unique variable or method names. The plastic surgery hypothesis is a well-known insight for APR, which states that the code ingredients to fix the bug usually already exist within the same project. Traditional APR tools have largely leveraged the plastic surgery hypothesis by designing manual or heuristic-based approaches to exploit such existing code ingredients. However, as recent APR research starts focusing on LLM-based approaches, the plastic surgery hypothesis has been largely ignored. In this paper, we ask the following question: How useful is the plastic surgery hypothesis in the era of LLMs? Interestingly, LLM-based APR presents a unique opportunity to fully automate the plastic surgery hypothesis via fine-tuning and prompting. To this end, we propose FitRepair, which combines the direct usage of LLMs with two domain-specific fine-tuning strategies and one prompting strategy for more powerful APR. Our experiments on the widely studied Defects4j 1.2 and 2.0 datasets show that FitRepair fixes 89 and 44 bugs (substantially outperforming the best-performing baseline by 15 and 8), respectively, demonstrating a promising future of the plastic surgery hypothesis in the era of LLMs.
研究动机与目标
- 在大型语言模型时代的 APR 中重新审视可塑性假设。
- 开发一个充分自动化的框架,利用项目特定信息来引导 LLM 进行修复。
- 提出两种领域特定的微调策略和一种提示技术以改进补丁生成。
- 在 Defects4j 1.2 和 2.0 上验证有效性并通过消融研究分析影响。
提出的方法
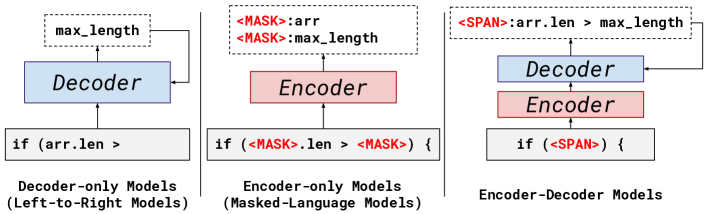
- 在 CodeT5(基于 MSP 的编码器-解码器 LLM)上实现 FitRepair。
- 引入 Knowledge-Intensified 微调,采用激进的 50% 令牌屏蔽以学习项目特定令牌。
- 引入 Repair-Oriented 微调,使每个样本只屏蔽一个连续的代码序列以与修复任务对齐。
- 提出 Relevant-Identifier 提示,利用信息检索和静态分析向模型提供与缺陷相关的标识符。
- 将四种模型变体(基础 CodeT5、两种微调模型和提示版本)的补丁合并,按似然性排序,并通过测试验证以选择合理且正确的补丁。
实验结果
研究问题
- RQ1RQ1: FitRepair 在 Defects4j 1.2 和 2.0 上与最新的 APR 工具相比如何?
- RQ2RQ2: 不同的 FitRepair 配置(微调策略和提示)的修复性能有何影响?
- RQ3RQ3: FitRepair 对修复来自不同项目的额外缺陷的泛化能力如何?
主要发现
- FitRepair 在 Defects4j 1.2 上修复 89 个缺陷,在 Defects4j 2.0 上修复 44 个缺陷,分别比最佳基线多出 15 和 8 个缺陷。
- 一次全面的消融研究证明了设计选择的合理性,并展示了结合微调与提示策略的好处。
- 该方法表明将可塑性假设与 LLM 相结合可以显著提升 APR,并且是全自动且具通用性的。
- 即使通过提示提供的项目信息部分或不完全也能有效引导 LLM 生成正确的补丁。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。