[论文解读] Revisiting Zeroth-Order Optimization for Memory-Efficient LLM Fine-Tuning: A Benchmark
本文基于多种模型家族、任务和微调方案,对无梯度传播的零阶优化方法在内存高效微调大型语言模型中的表现进行基准测试,并提出改进。
In the evolving landscape of natural language processing (NLP), fine-tuning pre-trained Large Language Models (LLMs) with first-order (FO) optimizers like SGD and Adam has become standard. Yet, as LLMs grow {in size}, the substantial memory overhead from back-propagation (BP) for FO gradient computation presents a significant challenge. Addressing this issue is crucial, especially for applications like on-device training where memory efficiency is paramount. This paper proposes a shift towards BP-free, zeroth-order (ZO) optimization as a solution for reducing memory costs during LLM fine-tuning, building on the initial concept introduced by MeZO. Unlike traditional ZO-SGD methods, our work expands the exploration to a wider array of ZO optimization techniques, through a comprehensive, first-of-its-kind benchmarking study across five LLM families (Roberta, OPT, LLaMA, Vicuna, Mistral), three task complexities, and five fine-tuning schemes. Our study unveils previously overlooked optimization principles, highlighting the importance of task alignment, the role of the forward gradient method, and the balance between algorithm complexity and fine-tuning performance. We further introduce novel enhancements to ZO optimization, including block-wise descent, hybrid training, and gradient sparsity. Our study offers a promising direction for achieving further memory-efficient LLM fine-tuning. Codes to reproduce all our experiments are at https://github.com/ZO-Bench/ZO-LLM .
研究动机与目标
- 评估与一阶方法相比,基于 BP-free 的零阶优化在 LLM 微调中的内存效率和准确性。
- 在五大 LLM 家族和三种任务复杂度下基准测试六种零阶优化方法。
- 识别影响零阶优化在 LLM 微调中性能的优化原则和任务对齐因素。
- 提出对 ZO 方法的改进(分块式、混合 ZO/FO、稀疏性)以提升内存效率和准确性。
提出的方法
- 回顾并对可用于 LLM 微调的零阶优化方法进行分类(ZO-SGD、ZO-SGD-Sign、ZO-SGD-MMT、ZO-SGD-Cons、ZO-Adam、Forward-Grad)。
- 使用带方向导数解释的随机梯度估计器(RGE)来近似一阶梯度。
- 通过比较将微调任务与预训练目标对齐的提示来研究任务对齐。
- 在五大 LLM 家族(Roberta-Large、OPT、LLaMA2、Vicuna、Mistral)、三种任务复杂度(SST2、COPA、WinoGrande)和五种微调方案(FT、LoRA、Prefix、Prompt 等)上进行大规模基准测试。
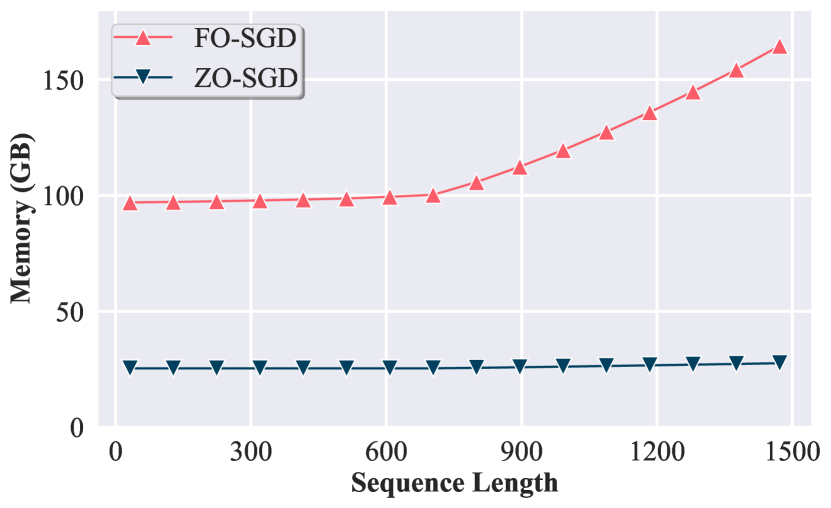
- 评估每次迭代的内存、显卡使用与运行时,以比较无BP与一阶方法。
- 探索改进:分块零阶、混合 ZO/FO 训练,以及稀疏性诱导的零阶梯度估计。
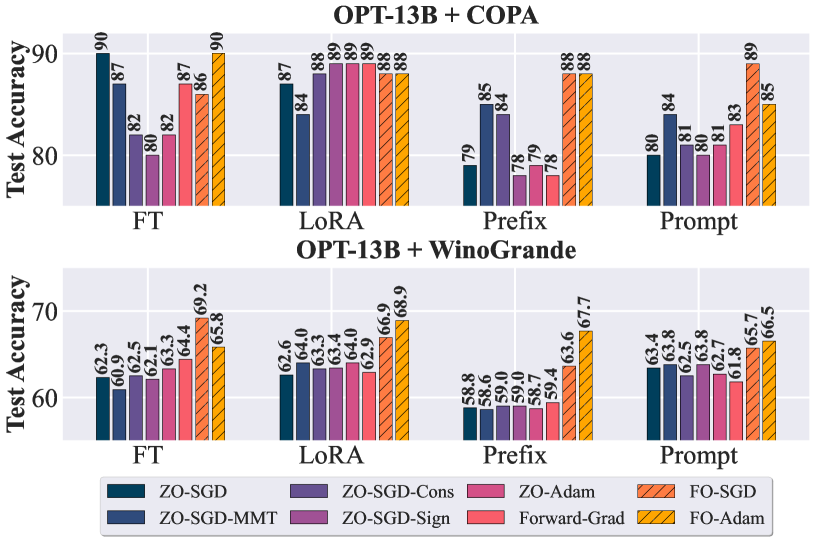
实验结果
研究问题
- RQ1全面基准测试是否能揭示零阶优化在 LLM 微调中的准确性与内存效率之间的权衡?
- RQ2任务对齐、前向梯度和算法复杂度如何影响跨模型规模的基于 ZO 的微调性能?
- RQ3如分块优化、混合 ZO/FO 与梯度稀疏性等改进,是否在保持内存优势的同时提高 ZO 微调性能?
- RQ4在 PEFT 方案与模型家族之间,ZO 方法相对于前向梯度与一阶优化器的表现如何?
主要发现
- 在某些设定下,零阶优化可以取得具有竞争力的结果,但在模型和任务之间呈现较高的方差。
- 在查询预算充足时,前向梯度可以超越许多零阶方法,但当模型更大或不兼容混合精度训练时,其内存效率优势会下降。
- ZO-SGD-Cons 与 ZO-SGD-MMT 在若干设定下表现稳定,而 ZO-SGD-Sign 常性能较差,除非在简单提示上。
- 基于提示的任务对齐对 ZO 性能影响显著;若缺乏对齐,ZO 方法的准确性会显著下降。
- 基于 LoRA 的微调在多种 ZO 方法中表现出鲁棒性,表明与高效内存训练策略兼容。
- 在更大模型和更复杂任务上,一阶方法通常比零阶方法明显更优,突出零阶方法的可扩展性限制。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。