[论文解读] Reward Design with Language Models
本文提出将大型语言模型作为代理奖励函数,通过自然语言提示来训练强化学习代理,从而实现对用户目标的少样本或零样本指定,并在Ultimatum Game、Matrix Games和DealOrNoDeal谈判中展示出具有竞争力的对齐效果。
Reward design in reinforcement learning (RL) is challenging since specifying human notions of desired behavior may be difficult via reward functions or require many expert demonstrations. Can we instead cheaply design rewards using a natural language interface? This paper explores how to simplify reward design by prompting a large language model (LLM) such as GPT-3 as a proxy reward function, where the user provides a textual prompt containing a few examples (few-shot) or a description (zero-shot) of the desired behavior. Our approach leverages this proxy reward function in an RL framework. Specifically, users specify a prompt once at the beginning of training. During training, the LLM evaluates an RL agent's behavior against the desired behavior described by the prompt and outputs a corresponding reward signal. The RL agent then uses this reward to update its behavior. We evaluate whether our approach can train agents aligned with user objectives in the Ultimatum Game, matrix games, and the DealOrNoDeal negotiation task. In all three tasks, we show that RL agents trained with our framework are well-aligned with the user's objectives and outperform RL agents trained with reward functions learned via supervised learning
研究动机与目标
- 激发更容易、直观的奖励设定,超越人工设计的奖励或带标签的数据。
- 提出一种通用的RL框架,使用LLM作为代理奖励函数,而无需更改RL算法。
- 证明基于LLM的奖励可以比监督学习(SL)学习的奖励更好地使代理与用户目标对齐。
- 在多种交互任务中,对单-shot和多-shot提示下的方法进行评估。
提出的方法
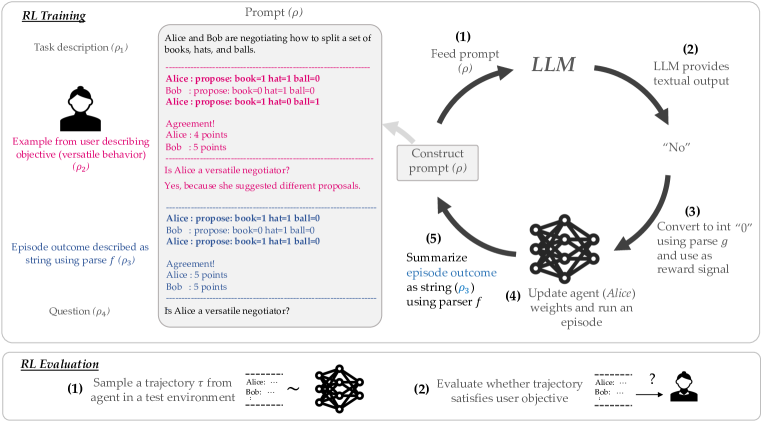
- 将问题形式化为一个MDP,其中奖励由给定任务提示和情节描述的LLM生成。
- 通过串联任务描述、用户指定的目标(示例或描述)、情节结果以及关于目标是否满足的问句来构造提示rho。
- 用任务特定的解析器g对LLM输出进行解析,以获得用于RL更新的标量奖励。
- 使用LLM派生的奖励,用任何RL算法训练代理。
- 评估LLM奖励信号的标注准确性及下游RL代理的表现相对于真值奖励的表现。
- 进行初步的人类用户研究以评估主观对齐与用户目标的一致性。
实验结果
研究问题
- RQ1Q1:LLMs是否能够在少样本提示下产生与用户目标一致的奖励信号?
- RQ2Q2:在零样本提示下,LLMs是否能够针对众所周知的目标产生目标一致的奖励?
- RQ3Q3:LLMs是否能够在如谈判等更长时程的任务中提供目标对齐的奖励?
主要发现
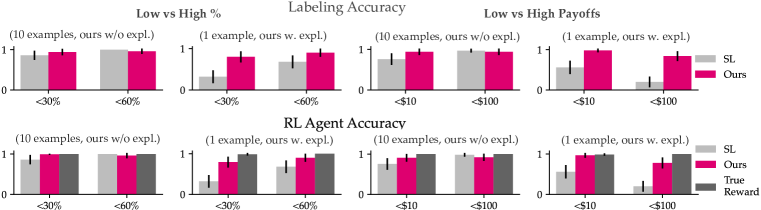
- LLMs在少样本提示下提供与用户目标一致的奖励信号,且解释显著提高准确性。
- 在矩阵博弈中,零样本提示对于众所周知的概念产生目标对齐的奖励,提升标注准确性,相较于无目标基线。
- 在 DealOrNoDeal 中,基于LLM的奖励使RL代理的准确性平均提升46%,并在4%之内接近真实奖励的表现。
- 初步用户研究表明,与用户指定风格对齐的代理获得显著更高的对齐评分(p<0.001)。
- 与SL基线相比,LLM奖励数据效率更高;SL需要数百个更多标注样本才能达到相似准确度。
- 提示设计的鲁棒性分析表明解释是提高准确性的关键因素,且提示对措辞变化具有相对鲁棒性。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。