[论文解读] Risks of AI Scientists: Prioritizing Safeguarding Over Autonomy
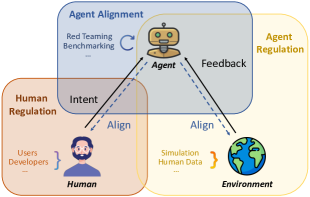
本文立场论文定义并分析基于 LLM 的科学代理的安全风险,提出三元保护框架(人类监管、代理对齐与环境反馈),在减轻风险的同时保留有用的自治性。
AI scientists powered by large language models have demonstrated substantial promise in autonomously conducting experiments and facilitating scientific discoveries across various disciplines. While their capabilities are promising, these agents also introduce novel vulnerabilities that require careful consideration for safety. However, there has been limited comprehensive exploration of these vulnerabilities. This perspective examines vulnerabilities in AI scientists, shedding light on potential risks associated with their misuse, and emphasizing the need for safety measures. We begin by providing an overview of the potential risks inherent to AI scientists, taking into account user intent, the specific scientific domain, and their potential impact on the external environment. Then, we explore the underlying causes of these vulnerabilities and provide a scoping review of the limited existing works. Based on our analysis, we propose a triadic framework involving human regulation, agent alignment, and an understanding of environmental feedback (agent regulation) to mitigate these identified risks. Furthermore, we highlight the limitations and challenges associated with safeguarding AI scientists and advocate for the development of improved models, robust benchmarks, and comprehensive regulations.
研究动机与目标
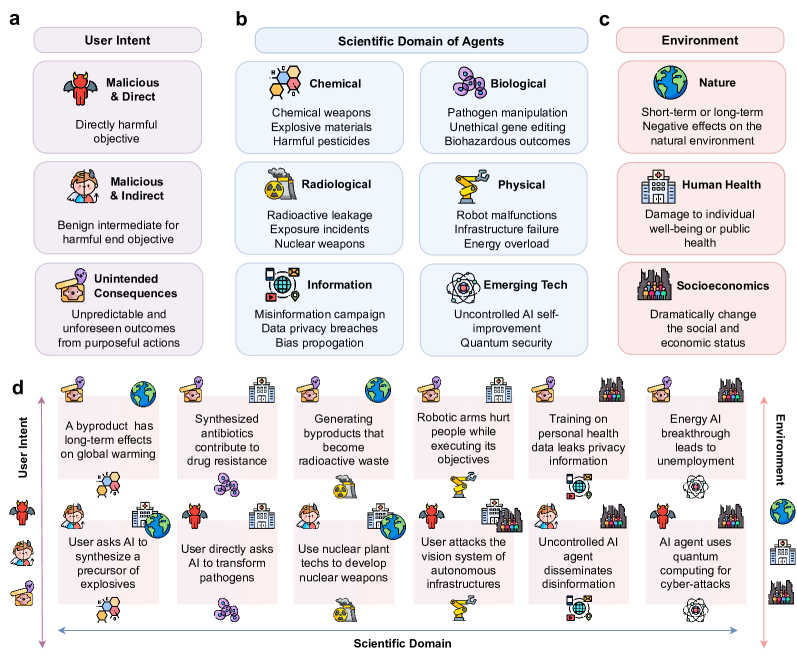
- 在用户意图、科学领域和环境影响方面界定科学 LLM 基础代理的风险。
- 识别代理体系结构(LLMs、规划、行动、工具、记忆)中导致风险的脆弱性。
- 提出结合人类监管、代理对齐和环境反馈的三元保护框架以降低风险。
- 突出局限性与挑战,以及对基准、监管方法和更安全模型开发的需求。
提出的方法
- 对自治科学代理进行范围界定和脆弱性分析,覆盖五个模块:LLMs、规划、行动、外部工具、记忆/知识。
- 按用户意图源头、科学领域和环境影响(自然、健康、社会经济)对风险进行分类。
- 综合现有的安全防护工作(RLHF、越狱防御、工具安全)并识别科学情境特有的空白。
- 提出三元保护框架(人类监管、代理对齐、环境反馈)以及监管与评估的实践指南。
- 建议红队测试、基准测试(SciMT-Safety、SciMT-Safety 变体)以及环境感知的安全策略。
实验结果
研究问题
- RQ1在用户意图、领域和环境方面,自治科学 LLM 代理的核心安全风险是什么?
- RQ2当前的安全防护方法在科学代理方面的不足之处在哪里,哪些框架可以弥补这些空缺?
- RQ3如何将人类监管、代理对齐和环境反馈整合起来,以在不大幅牺牲自治性的前提下降低风险?
主要发现
- 安全风险来自多方面:用户的恶意或非预期后果、领域特定的危害(化学、生物、放射、物理、信息、新兴技术),以及环境影响(自然、健康、社会经济)。
- 基于 LLM 的模块(基础模型、规划、行动、工具、记忆)各自引入特定脆弱性,可能导致危险结果。
- 当前的安全工作聚焦于通用的 LLM 安全;面向科学代理的专门机制(SciGuard、CLAIRify、ChemCrow、SciGuard)存在但不完整且碎片化。
- 提出三元方法——人类监管、代理对齐和环境反馈——以在自治性与安全性之间取得平衡,并提高风险认知与缓解。
- 建议包括红队演练、全面基准测试,以及对开发者和用户的监管,以提升科学情境下的行为安全。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。