[论文解读] rKAN: Rational Kolmogorov-Arnold Networks
本文介绍两种基于有理基的 Kolmogorov-Arnold Networks (rKAN):Padé 近似和有理 Jacobi 映射,并在回归、MNIST 分类和物理信息约束的微分方程任务中对它们进行评估。
The development of Kolmogorov-Arnold networks (KANs) marks a significant shift from traditional multi-layer perceptrons in deep learning. Initially, KANs employed B-spline curves as their primary basis function, but their inherent complexity posed implementation challenges. Consequently, researchers have explored alternative basis functions such as Wavelets, Polynomials, and Fractional functions. In this research, we explore the use of rational functions as a novel basis function for KANs. We propose two different approaches based on Pade approximation and rational Jacobi functions as trainable basis functions, establishing the rational KAN (rKAN). We then evaluate rKAN's performance in various deep learning and physics-informed tasks to demonstrate its practicality and effectiveness in function approximation.
研究动机与目标
- 通过使用有理基函数来改进函数逼近并处理渐近行为,激发并克服传统 KAN 的局限性。
- 开发两种具体的 rKAN 架构:基于 Padé 的有理函数和映射的有理 Jacobi 函数。
- 评估 rKAN 在合成回归任务、MNIST 分类以及物理信息约束的微分方程问题上的性能。
- 与现有的 KAN 变体和基线激活函数进行比较,以确立其实际可行性。
提出的方法
- 通过两种方法为 KAN 定义有理基函数:使用 Jacobi 推导的多项式比值的 Padé 近似(带可训练系数);以及通过将 Jacobi 多项式映射到有限域或无穷域得到的有理 Jacobi 函数。
- 在 Padé-rKAN 中,φ_{q,k}(ξ) = (sum_{i=0}^{k} θ^e_i R^{(α,β)}_i(ξ_q)) / (sum_{i=0}^{p} θ^d_i R^{(α,β)}_i(ξ_q)),其中 ξ 的输入被激活函数 σ(·) 限定,且可优化的 α、β、ι 超参数。
- 在 Jacobi-rKAN 中,φ_{q,k}(ξ) = J^{(α,β)}_k(φ(ξ_q)),其中 φ 是一个非线性有理映射(有限/半无限/无限区间),SoftPlus 控制可训练的 ι 以确保非负性。
- 在 Kolmogorov-Arnold 网络框架中将 φ 函数组合成 F(ξ) = sum_{k=1}^K ψ_k(sum_{q=1}^ν φ_{q,k}(σ(ξ_q))),其中 ψ_k 为线性函数。
- 通过约束映射在使用 φ(·) 作为映射 Jacobi 函数时将输入映射到正域并使用分数阶 γ,来研究分数阶有理 KAN 变体。
- 在回归、带卷积神经网络骨干的 MNIST 分类,以及涉及 Lane-Emden 常微分方程和泊松型偏微分方程的物理信息深度学习任务中进行评估。
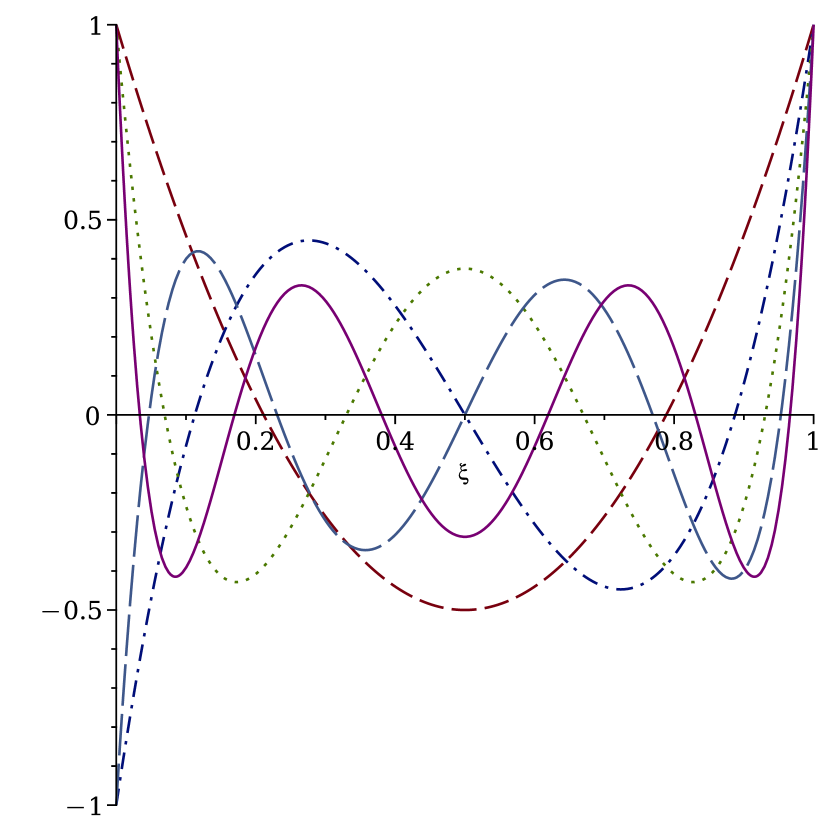
实验结果
研究问题
- RQ1在 KAN 中的有理基函数是否能相对于传统的 KAN 变体提升对具有渐近行为或奇点的函数的近似?
- RQ2基于 Padé 的和映射 Jacobi 的 rKAN 在回归、分类和物理信息问题上的准确性与训练复杂度相比如何?
- RQ3超参数 α、β 以及映射/ι 在优化过程中的模型性能与稳定性上的影响是什么?
- RQ4rKAN 在用于求解 Lane-Emden 方程和椭圆型 PDE 的物理信息神经网络中是否具有实际优势?
主要发现
- 在合成回归任务中,rKAN 变体在 F1、F2、F3 下的均方误差 (MSE) 与 fKAN、Jacobi-rKAN 和标准 KAN 相比具竞争力甚至优越,且在不同 K 值下。
- 在 MNIST 上,Jacobi-rKAN 和 rKAN(多 K 配置)达到较高准确率(如 rKAN(5) 可达 99.293%),并且相对于基线和某些 fKAN 配置具有更优的损失。
- 在物理信息测试中,Jacobi-rKAN 和 Padé-rKAN 在 Lane-Emden 问题中获得小的一阶根误差,且残差与某些 GEPINN 配置相比相当或更好,具体数值见表 5。
- 使用四层 Jacobi-rKAN 的椭圆 PDE 近似得到合理的预测和可解释的残差,展示了对 PDE 的适用性。
- Padé-rKAN 可以提高准确性,但由于多项式计算,训练时间增加,凸显了准确性与效率之间的权衡。
- 该方法在合适的情景下支持与分数阶 KAN 的整合,表明在问题域之间具有灵活性。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。