[论文解读] RLEF: Grounding Code LLMs in Execution Feedback with Reinforcement Learning
RLEF 通过强化学习在多轮对话中利用执行反馈来训练代码生成的大型语言模型,在 CodeContests 上达到最先进的求解率,且所需样本更少,并将收益扩散到 HumanEval+ 和 MBPP+。
Large language models (LLMs) deployed as agents solve user-specified tasks over multiple steps while keeping the required manual engagement to a minimum. Crucially, such LLMs need to ground their generations in any feedback obtained to reliably achieve the desired outcomes. We propose an end-to-end reinforcement learning method for teaching models to leverage execution feedback in the realm of code synthesis, where state-of-the-art LLMs struggle to improve code iteratively compared to independent sampling. We benchmark on competitive programming tasks, where we achieve new state-of-the art results with both small (8B parameters) and large (70B) models while reducing the amount of samples required by an order of magnitude. Our analysis of inference-time behavior demonstrates that our method produces LLMs that effectively leverage automatic feedback over multiple steps.
研究动机与目标
- 以环境反馈为基础,对代码生成 LLM 的 grounding 以改善迭代修复与最终正确性进行动机驱动
- 提出一个端到端的 RL 框架(RLEF),使用代码执行结果作为奖励
- 证明 RLEF 能在较小的模型和更少样本的情况下提升 CodeContests 等竞赛基准的求解率
- 演示 RLEF 的改进可泛化到其他代码生成基准(HumanEval+、MBPP+)以及更高轮次预算的情况
提出的方法
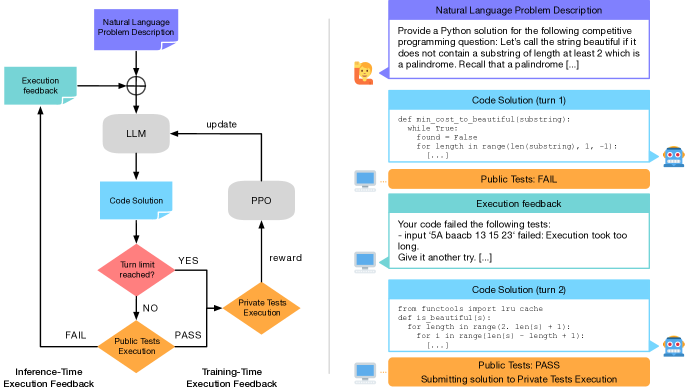
- 将迭代代码合成建模为一个多轮对话,每轮生成代码并接收执行反馈
- 使用两组测试集(训练期间用于反馈的公共集,最终评估的私有集)以避免信息泄露并确保鲁棒评估
- 将问题 framing 为部分可观测的马尔可夫决策过程,并使用带 KL 惩罚的近端策略优化(PPO)对初始策略进行正则化
- 将策略视为逐字节的动作,并结合一个回合级价值函数,从而实现基于反馈的更新
- 结合二元最终奖励以及对无效代码的惩罚和一个 KL 项以平衡探索与保真度
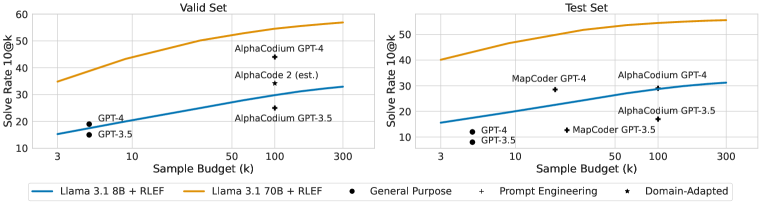
实验结果
研究问题
- RQ1强化学习结合执行反馈是否能在独立采样之外提升迭代代码合成的效果
- RQ2RLEF 是否使 LLM 能够在多轮对话中有效利用上下文中的执行反馈
- RQ3RLEF 的改进是否能泛化到 CodeContests 以外的其他代码生成基准
- RQ4RLEF 如何影响小型与大型模型在样本效率与轮次预算利用上的表现
主要发现
- RLEF 训练的模型在 CodeContests 上对 8B 与 70B 的 LLM 达到新的最先进结果,同时显著降低样本需求
- 在测试集上,70B 模型经 RLEF 处理后在 (1@3) 达到 37.5,(1ex+RLEF 1@3) 达到 40.1,超越了以往方法
- RLEF 的改进可转移至 HumanEval+ 与 MBPP+ 基准,并在增加样本预算时仍然成立
- 推理阶段的反馈实现多轮自我修复和多样化但有针对性的编辑,降低对独立采样的依赖
- 使用真实反馈比随机反馈带来更大收益,表明该方法依赖于有意义的执行信号
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。