[论文解读] RoBERTa-BiLSTM: A Context-Aware Hybrid Model for Sentiment Analysis
本文提出 RoBERTa-BiLSTM,一种混合模型,使用 RoBERTa 生成词嵌入,利用 BiLSTM 捕捉长程依赖,在三个数据集上实现最先进的情感分析结果。
Effectively analyzing the comments to uncover latent intentions holds immense value in making strategic decisions across various domains. However, several challenges hinder the process of sentiment analysis including the lexical diversity exhibited in comments, the presence of long dependencies within the text, encountering unknown symbols and words, and dealing with imbalanced datasets. Moreover, existing sentiment analysis tasks mostly leveraged sequential models to encode the long dependent texts and it requires longer execution time as it processes the text sequentially. In contrast, the Transformer requires less execution time due to its parallel processing nature. In this work, we introduce a novel hybrid deep learning model, RoBERTa-BiLSTM, which combines the Robustly Optimized BERT Pretraining Approach (RoBERTa) with Bidirectional Long Short-Term Memory (BiLSTM) networks. RoBERTa is utilized to generate meaningful word embedding vectors, while BiLSTM effectively captures the contextual semantics of long-dependent texts. The RoBERTa-BiLSTM hybrid model leverages the strengths of both sequential and Transformer models to enhance performance in sentiment analysis. We conducted experiments using datasets from IMDb, Twitter US Airline, and Sentiment140 to evaluate the proposed model against existing state-of-the-art methods. Our experimental findings demonstrate that the RoBERTa-BiLSTM model surpasses baseline models (e.g., BERT, RoBERTa-base, RoBERTa-GRU, and RoBERTa-LSTM), achieving accuracies of 80.74%, 92.36%, and 82.25% on the Twitter US Airline, IMDb, and Sentiment140 datasets, respectively. Additionally, the model achieves F1-scores of 80.73%, 92.35%, and 82.25% on the same datasets, respectively.
研究动机与目标
- 在词汇多样性、长依赖和数据不平衡的多样化在线评论中进行情感分析的动机。
- 提出一种上下文感知的混合模型,将 RoBERTa 的嵌入与 BiLSTM 相结合以提升性能。
- 在多个数据集上评估 RoBERTa-BiLSTM 与先进基线的比较。
- 分析数据预处理和超参数调优对模型性能的影响。
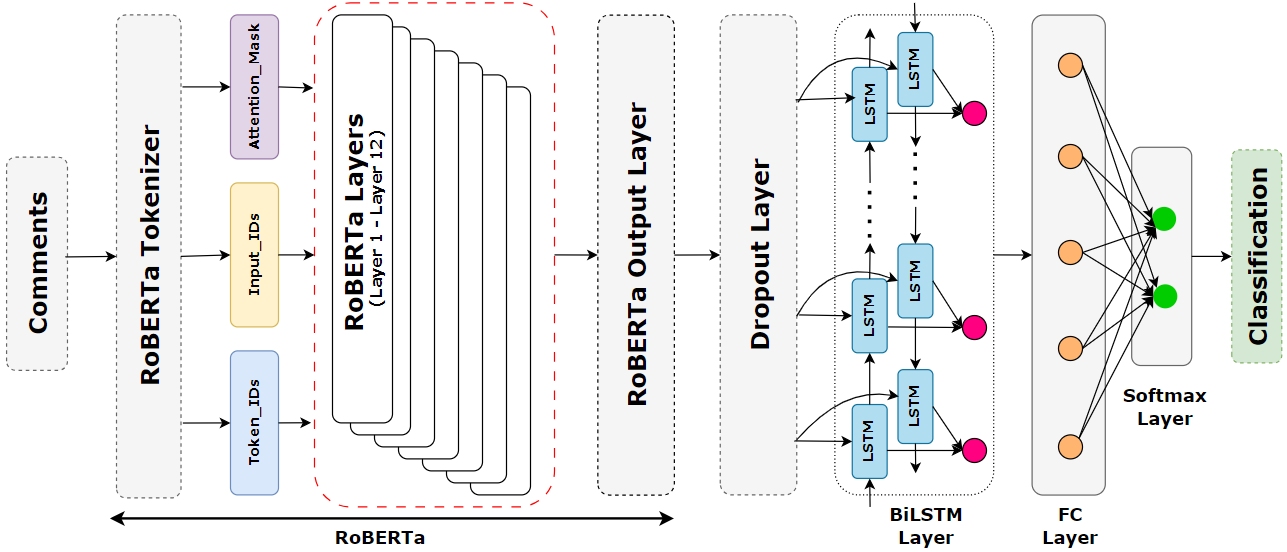
提出的方法
- 将 RoBERTa 作为编码器,用来生成上下文词嵌入。
- 将 RoBERTa 嵌入输入 BiLSTM,并加入 dropout 层以捕捉长程依赖。
- 增加一个全连接层和 Softmax 分类器,将 BiLSTM 的输出映射到情感类别。
- 在 RoBERTa 分词前应用数据预处理,包括小写化、噪声去除和词形还原。
- 调整超参数(学习率、隐藏单元数量)并与 LSTM/GRU 变体进行比较。
- 使用交叉熵损失进行多类情感分类。
实验结果
研究问题
- RQ1RoBERTa-BiLSTM 混合模型是否能够在情感分析任务中超过标准 RoBERTa 变体(base、GRU、LSTM)?
- RQ2数据预处理选择和超参数调优对模型性能的影响是什么?
- RQ3模型在具有不同类别分布的 diverse 数据集(IMDb、Twitter US Airline、Sentiment140)上的表现如何?
主要发现
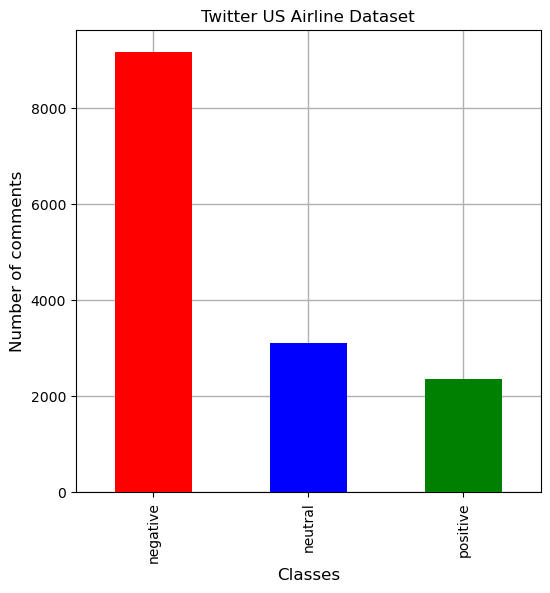
- RoBERTa-BiLSTM 在 Twitter US Airline 上达到 80.74% 的准确率。
- RoBERTa-BiLSTM 在 IMDb 上达到 92.36% 的准确率。
- RoBERTa-BiLSTM 在 Sentiment140 上达到 82.25% 的准确率。
- RoBERTa-BiLSTM 的 F1 分数分别为 80.73%(Twitter US Airline)、92.35%(IMDb)和 82.25%(Sentiment140)。
- 该模型在评估数据集上优于 RoBERTa-base、RoBERTa-GRU、RoBERTa-LSTM 基线。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。