[论文解读] Robust Distortion-free Watermarks for Language Models
本论文提出了无失真、鲁棒的水印,适用于自回归语言模型,检测与模型无关,并在对 OPT-1.3B、LLaMA-7B 和 Alpaca-7B 进行大量编辑后验证了强检测性。
We propose a methodology for planting watermarks in text from an autoregressive language model that are robust to perturbations without changing the distribution over text up to a certain maximum generation budget. We generate watermarked text by mapping a sequence of random numbers -- which we compute using a randomized watermark key -- to a sample from the language model. To detect watermarked text, any party who knows the key can align the text to the random number sequence. We instantiate our watermark methodology with two sampling schemes: inverse transform sampling and exponential minimum sampling. We apply these watermarks to three language models -- OPT-1.3B, LLaMA-7B and Alpaca-7B -- to experimentally validate their statistical power and robustness to various paraphrasing attacks. Notably, for both the OPT-1.3B and LLaMA-7B models, we find we can reliably detect watermarked text ($p \leq 0.01$) from $35$ tokens even after corrupting between $40$-$50\%$ of the tokens via random edits (i.e., substitutions, insertions or deletions). For the Alpaca-7B model, we conduct a case study on the feasibility of watermarking responses to typical user instructions. Due to the lower entropy of the responses, detection is more difficult: around $25\%$ of the responses -- whose median length is around $100$ tokens -- are detectable with $p \leq 0.01$, and the watermark is also less robust to certain automated paraphrasing attacks we implement.
研究动机与目标
- 提升对由语言模型生成文本的溯源与归属的动机。
- 开发不会改变原始文本分布的水印(无失真)。
- 创建一个模型无关的检测器,无需了解提示信息。
- 确保在文本扰动(如编辑和意译)下水印检测的鲁棒性。
提出的方法
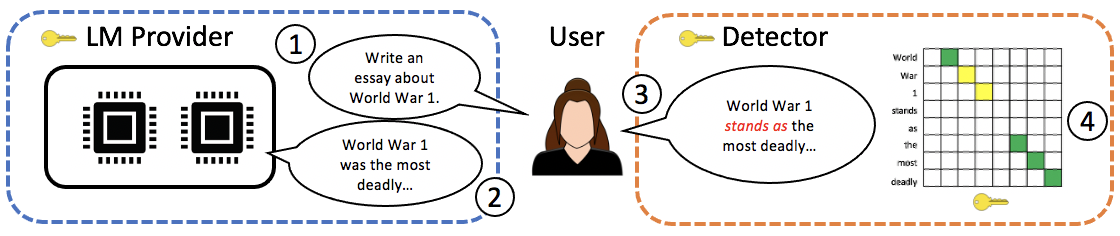
- 定义一个水印协议,在语言模型提供者和检测器之间共享水印密钥。
- 引入一个 generate 函数,将随机密钥序列映射到模型样本,同时保持模型分布(无失真)。
- 定义一个 detect 函数,利用鲁棒的序列对齐来测试文本是否依赖水印密钥,并输出一个 p 值。
- 实现两种采样方案:逆变换采样和指数最小采样。
- 提供一个随机化包装器 shift_generate,以避免在不同查询中重复使用相同的水印子序列并维持随机性。
- 证明解码器的无失真性并推导随文本长度及水印密钥长度扩展的 p 值界限。
实验结果
研究问题
- RQ1如何在语言模型输出中嵌入水印而不扭曲输出分布?
- RQ2在大量文本编辑或意译后,水印是否仍能鲁棒检测?
- RQ3在给定水印潜力和文本长度的情况下,探测能力(p 值)的理论极限是什么?
- RQ4不同的采样策略(逆变换 vs 指数最小)在效力和鲁棒性方面有何比较?
主要发现
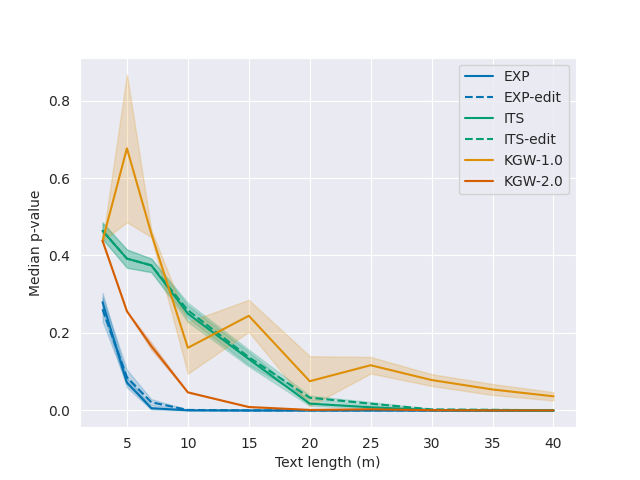
- 水印是无失真的:当对水印密钥序列求平均时,generate 函数产生的文本与基础语言模型的分布相同。
- 检测能力随文本长度呈指数增加,随水印密钥长度仅线性下降。
- 使用指数最小采样时,检测器在 OPT-1.3B 和 LLaMA-7B 上在 35 tokens 时就可达到 p ≤ 0.01 的检测,即使在 40–50% 的 token 替换/编辑之后。
- 对于 Alpaca-7B,大约 25% 的回复(中位长度约为 100 tokens)可检测且 p ≤ 0.01,但对某些自动意译的鲁棒性较弱。
- 在对较大模型进行意译(翻译成法语/俄语再译回)后,水印检测仍然可行,但鲁棒性因模型而异。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。