[论文解读] RTMPose: Real-Time Multi-Person Pose Estimation based on MMPose
RTMPose 提出一个基于 MMPose 的实时自上而下的多人人姿态估计框架,使用 SimCC 基于坐标分类、CSPNeXt 骨干,以及部署友好优化,在 CPU、GPU 和移动设备上实现高精度、低延迟。
Recent studies on 2D pose estimation have achieved excellent performance on public benchmarks, yet its application in the industrial community still suffers from heavy model parameters and high latency. In order to bridge this gap, we empirically explore key factors in pose estimation including paradigm, model architecture, training strategy, and deployment, and present a high-performance real-time multi-person pose estimation framework, RTMPose, based on MMPose. Our RTMPose-m achieves 75.8% AP on COCO with 90+ FPS on an Intel i7-11700 CPU and 430+ FPS on an NVIDIA GTX 1660 Ti GPU, and RTMPose-l achieves 67.0% AP on COCO-WholeBody with 130+ FPS. To further evaluate RTMPose's capability in critical real-time applications, we also report the performance after deploying on the mobile device. Our RTMPose-s achieves 72.2% AP on COCO with 70+ FPS on a Snapdragon 865 chip, outperforming existing open-source libraries. Code and models are released at https://github.com/open-mmlab/mmpose/tree/1.x/projects/rtmpose.
研究动机与目标
- 调查影响实时二维多人人姿态估计性能的因素(范式、骨干网络、定位方法、训练、部署)。
- 开发一个在工业部署中平衡速度与精度的实时姿态估计框架。
- 展示在不同后端和检测器下对 CPU、GPU 和移动设备的可移植性。
- 提供开源模型与部署指南,促进行业采用。
提出的方法
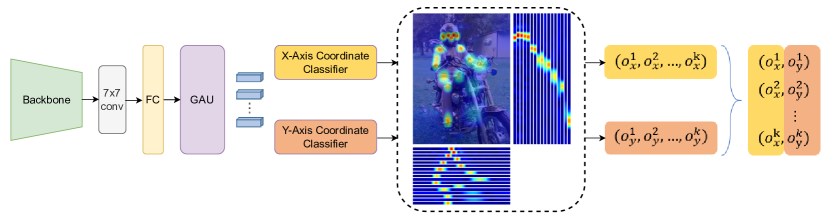
- 采用自上而下的流水线,使用高效检测器和每个人的轻量级姿态估计器。
- 使用 CSPNeXt 骨干,以实现良好的速度-精度平衡和部署友好性。
- 使用基于 SimCC 的坐标分类方法(x 和 y 分开)预测关键点,配以高斯柔标签和温度缩放。
- 引入自注意力细化(Gated Attention Unit)以提升关键点表征。
- 应用包括 UDP 预训练、EMA、平行余弦学习率,以及两阶段强增强再弱增强的训练策略。
- 通过跳帧检测、姿态 NMS(OKS 基基)和 OneEuro 平滑来优化推理流程;并在 PyTorch、ONNX Runtime、TensorRT 和 ncnn 上部署。
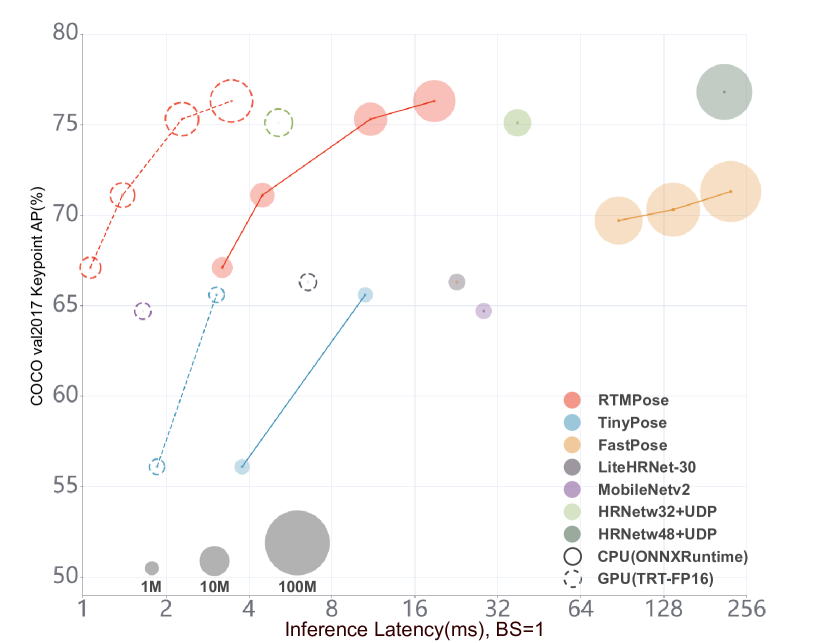
实验结果
研究问题
- RQ1哪种范式、骨干和定位方法在实时多人人姿态估计中实现最佳的速度-精度权衡?
- RQ2SimCC 基于坐标分类并进行有针对性的训练和架构选择,是否能够在保持或超越热图方法精度的同时降低计算量?
- RQ3部署优化和平台特定后端如何影响 CPU、GPU 和移动硬件上的实时性能?
主要发现
| 方法 | 骨干网络 | 检测器 | 检测输入尺寸 | 姿态输入尺寸 | GFLOPs | AP | 额外数据 |
|---|---|---|---|---|---|---|---|
| PaddleDetection TinyPose | Wider NLiteHRNet | YOLOv3 | 608x608 | 128x96 | 0.08 | 52.3 | |
| PaddleDetection TinyPose | Wider NLiteHRNet | YOLOv3 | 608x608 | 256x192 | 0.33 | 60.9 | |
| PaddleDetection TinyPose | Wider NLiteHRNet | Faster-RCNN | N/A | 128x96 | 0.08 | 56.1 | AIC(220K) |
| PaddleDetection TinyPose | Wider NLiteHRNet | Faster-RCNN | N/A | 256x192 | 0.33 | 65.6 | +Internal(unknown) |
| PaddleDetection TinyPose | Wider NLiteHRNet | PicoDet-s | 320x320 | 128x96 | 0.08 | 48.4 | |
| PaddleDetection TinyPose | Wider NLiteHRNet | PicoDet-s | 320x320 | 256x192 | 0.33 | 56.5 | |
| AlphaPose | FastPose | YoloV3 | 608x608 | 256x192 | 5.91 | 71.2 | - |
| MMPose | RTMPose-t | Faster-RCNN | N/A | 256x192 | 0.36 | 65.8 | - |
| MMPose | RTMPose-s | Faster-RCNN | N/A | 256x192 | 0.68 | 69.6 | - |
| MMPose | RTMPose-m | Faster-RCNN | N/A | 256x192 | 1.93 | 73.6 | - |
| MMPose | RTMPose-l | Faster-RCNN | N/A | 256x192 | 4.16 | 74.8 | - |
| MMPose | RTMPose-t | YOLOv3 | 608x608 | 256x192 | 0.36 | 66.0 | AIC(220K) |
| MMPose | RTMPose-s | YOLOv3 | 608x608 | 256x192 | 0.68 | 70.3 | |
| MMPose | RTMPose-m | YOLOv3 | 608x608 | 256x192 | 1.93 | 74.7 | |
| MMPose | RTMPose-l | YOLOv3 | 608x608 | 256x192 | 4.16 | 75.7 | |
| MMPose | RTMPose-m | RTMDet-nano | 320x320 | 256x192 | 1.93 | 73.2 | |
| MMPose | RTMPose-s | RTMDet-nano | 320x320 | 256x192 | 0.68 | 68.5 | |
| MMPose | RTMPose-m | RTMDet-nano | 320x320 | 256x192 | 1.93 | 73.2 | |
| MMPose | RTMPose-m | RTMDet-m | 640x640 | 256x192 | 1.93 | 75.7 | |
| MMPose | RTMPose-l | RTMDet-m | 640x640 | 256x192 | 4.16 | 76.6 |
- RTMPose-m 在 COCO 验证集上 AP 达到 75.8%,在 CPU 上超过 90 FPS,在 GTX 1660 Ti GPU 上超过 430 FPS。
- RTMPose-l 在 COCO 上 AP 为 74.8%,在报告的配置中 GFLOPs 为 76.6,显示出在中等计算量下的强大精度。
- RTMPose-s 在 COCO 上 AP 72.2%,在 Snapdragon 865 上超过 70 FPS,优于现有开源移动解决方案。
- 使用 SimCC 配合 CSPNeXt 骨干和基于 GAU 的 refined,与基于热图的方法相比在精度上具有竞争力,同时计算成本更低(如 CT 基线或变换器密集基线)。
- 两阶段训练(在 COCO 上通过 UDP 进行预训练,然后用强-弱增强微调)和 EMA 将 AP 提升数点(在消融实验中展示)。
- 跳帧检测和后处理(基于 OKS 的 NMS 和 OneEuro 滤波)降低延迟并在跨帧中提高姿态鲁棒性。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。