[论文解读] RWKV: Reinventing RNNs for the Transformer Era
RWKV 引入一种混合架构,结合 Transformer 的训练效率与 RNN 的推理效率,实现线性内存/计算复杂度扩展,并在参数规模与同等 Transformer 相当时(直至 14B 参数)具有竞争力。
Transformers have revolutionized almost all natural language processing (NLP) tasks but suffer from memory and computational complexity that scales quadratically with sequence length. In contrast, recurrent neural networks (RNNs) exhibit linear scaling in memory and computational requirements but struggle to match the same performance as Transformers due to limitations in parallelization and scalability. We propose a novel model architecture, Receptance Weighted Key Value (RWKV), that combines the efficient parallelizable training of transformers with the efficient inference of RNNs. Our approach leverages a linear attention mechanism and allows us to formulate the model as either a Transformer or an RNN, thus parallelizing computations during training and maintains constant computational and memory complexity during inference. We scale our models as large as 14 billion parameters, by far the largest dense RNN ever trained, and find RWKV performs on par with similarly sized Transformers, suggesting future work can leverage this architecture to create more efficient models. This work presents a significant step towards reconciling trade-offs between computational efficiency and model performance in sequence processing tasks.
研究动机与目标
- 解决 Transformer 在处理长序列时自注意力的内存和二次复杂度瓶颈。
- 提出一种可像 Transformer 那样训练、但像 RNN 那样推理的模型,在时间和空间上实现线性扩展。
- 证明 RWKV 能扩展到十亿级参数并在标准 NLP 基准测试中与 Transformer 基线具有竞争力。
- 提供预训练的 RWKV 模型,并展示在大规模序列建模中的实际收益。
提出的方法
- 引入 Receptance Weighted Key Value (RWKV) 架构,结合时间混合和通道混合块。
- 用线性时间的 WKV 运算符替代传统点积注意力,该运算符随时间按通道衰减。
- 使用 token shift 和时间相关 softmax 稳定梯度,便于深层堆叠并结合层归一化。
- 实现类似 Transformer 的时间并行训练,同时实现 RNN 式自回归推理。
- 应用自定义内核和初始化策略,以提高大模型的效率和收敛性。
实验结果
研究问题
- RQ1RWKV 是否能在保持线性推理成本的同时实现 Transformer 的训练并行性?
- RQ2在相似的计算预算下,RWKV 的规模和性能与二次变换结构相比如何?
- RQ3较长上下文处理和上下文长度对 RWKV 的性能与效率有何影响?
- RQ4在大规模语料上训练极大 RWKV 模型时,哪些优化与初始化策略更有效?
主要发现
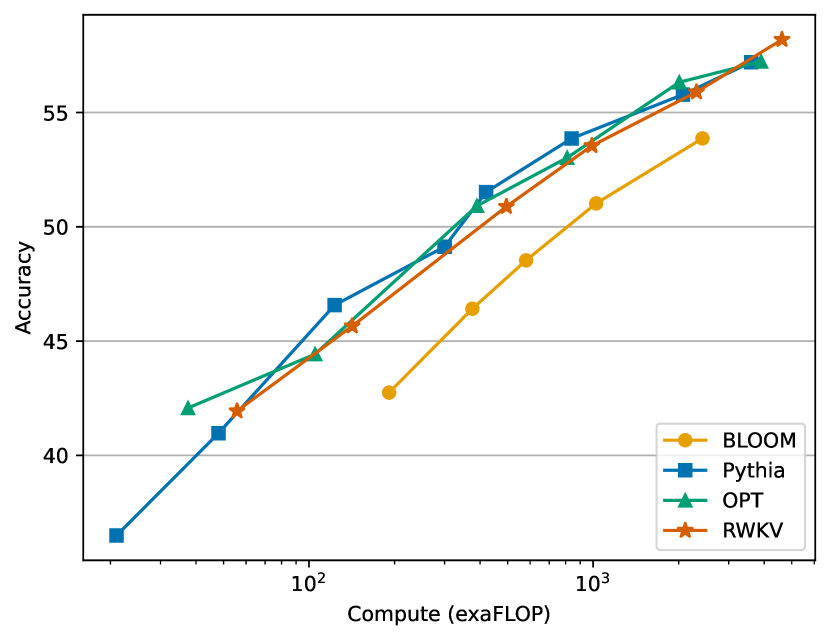
- RWKV 最大可达 14B 参数的模型可训练,并在与同等规模的 Transformer 相比时具有竞争性表现。
- RWKV 在序列长度上的推理成本呈线性,与 Transformer 的二次扩展形成对比。
- RWKV 遵循与 Transformer 相似的缩放形式,在损失与计算之间对不同模型规模有很强的拟合性。
- 在微调阶段增加上下文长度可降低测试损失,表明对长上下文信息的有效利用。
- RWKV 在标准 NLP 基准上的零-shot 结果具有竞争力,在 CPU/GPU 推理时文本生成的速度/内存表现也更有利。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。