[论文解读] Safeguarding Large Language Models: A Survey
一项关于 LLM 守护性 guardrails 的系统性文献综述,考察框架、评估指标、攻击与防御,以及实现一个全面的、多学科的 guardrail 设计的路径。
In the burgeoning field of Large Language Models (LLMs), developing a robust safety mechanism, colloquially known as "safeguards" or "guardrails", has become imperative to ensure the ethical use of LLMs within prescribed boundaries. This article provides a systematic literature review on the current status of this critical mechanism. It discusses its major challenges and how it can be enhanced into a comprehensive mechanism dealing with ethical issues in various contexts. First, the paper elucidates the current landscape of safeguarding mechanisms that major LLM service providers and the open-source community employ. This is followed by the techniques to evaluate, analyze, and enhance some (un)desirable properties that a guardrail might want to enforce, such as hallucinations, fairness, privacy, and so on. Based on them, we review techniques to circumvent these controls (i.e., attacks), to defend the attacks, and to reinforce the guardrails. While the techniques mentioned above represent the current status and the active research trends, we also discuss several challenges that cannot be easily dealt with by the methods and present our vision on how to implement a comprehensive guardrail through the full consideration of multi-disciplinary approach, neural-symbolic method, and systems development lifecycle.
研究动机与目标
- 了解当前在各提供商和开源社区中用于控制 LLM 输出的 guardrail 框架。
- 识别期望的属性(例如幻觉控制、公平、隐私、鲁棒性)以及如何评估/提升它们。
- 回顾针对 guardrails 的攻击方法、防御和强化策略,以增强 guardrails。
- 讨论挑战并提出一个覆盖开发生命周期的全面、多学科 guardrail 设计的路径。
提出的方法
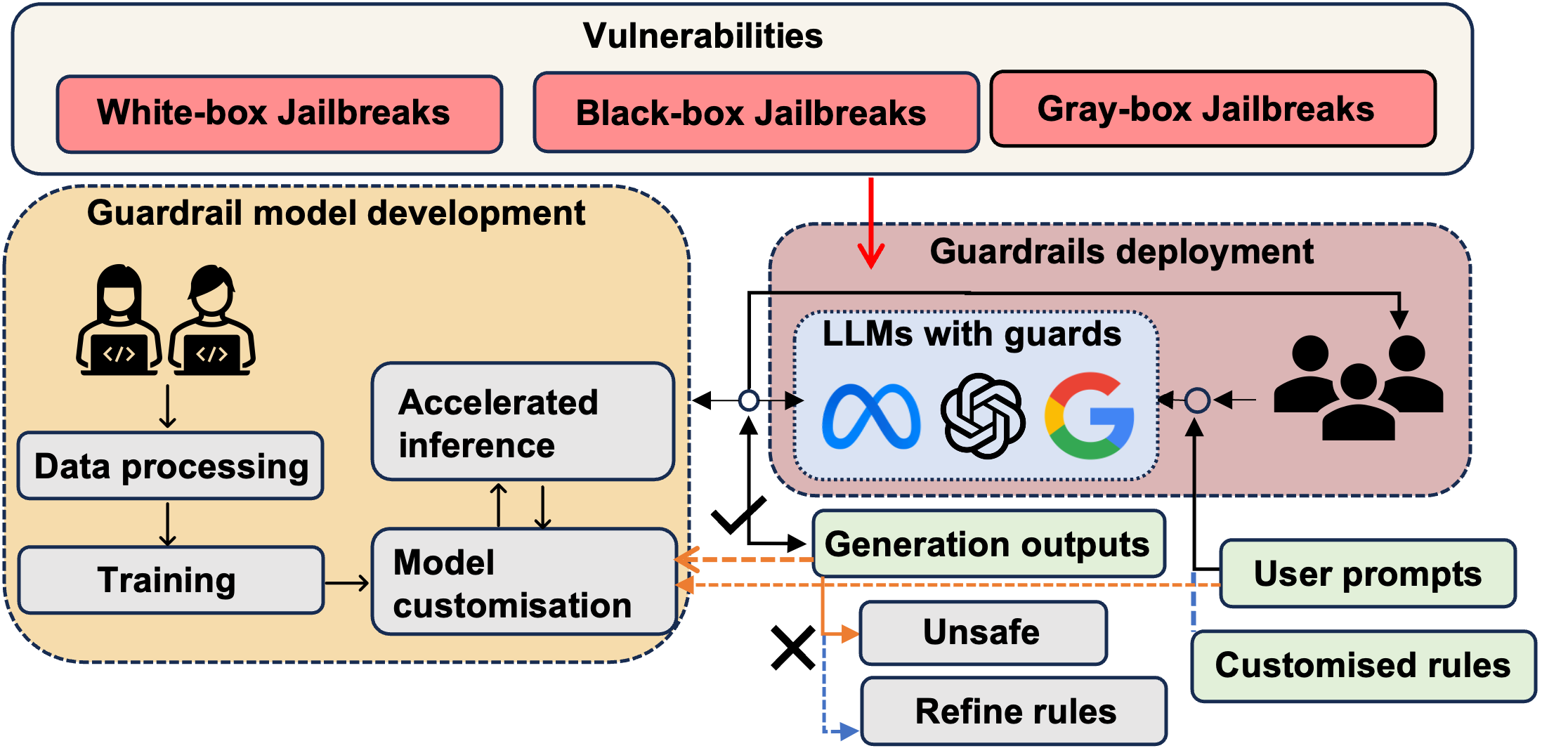
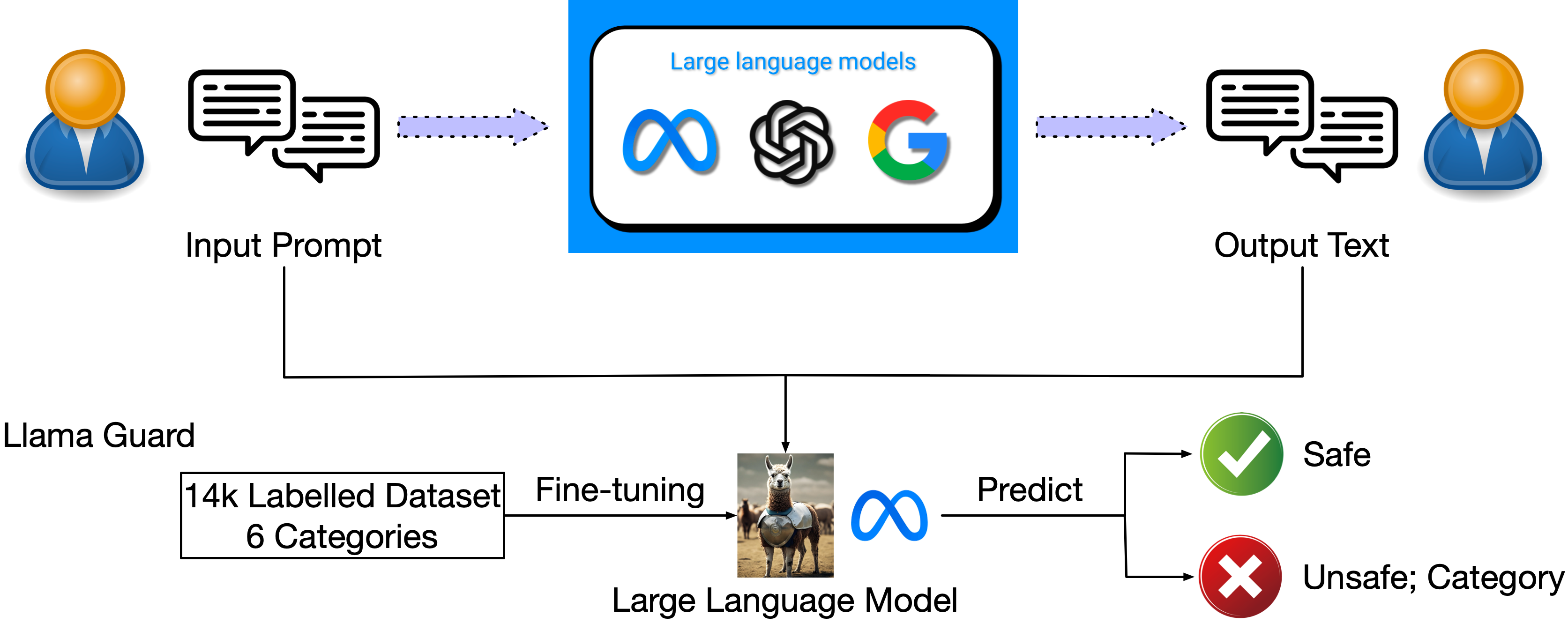
- 调研 guardrail 框架及支持的软件包(例如 Llama Guard、Nvidia NeMo、Guardrails AI、TruLens、Guidance AI、LMQL)。
- 分析 guardrails 如何强制执行诸如幻觉、公平、隐私、鲁棒性、毒性、法律性、OOD 和不确定性等属性。
- 检视与 guardrails 相关的攻击、防御和强化技术。
- 讨论受安全关键软件标准(如 ISO-26262、DO-178B/C)和神经-符号集成启发的设计考量。
- 强调用于实现或评估 guardrails 的工具和 Python 包(LangChain、AIF360、ART、Fairlearn、Detoxify)。
实验结果
研究问题
- RQ1在生产与开源环境中,目前部署哪些 guardrail 框架和工作流来控制 LLM 输出?
- RQ2guardrails 应该强制哪些属性,以及如何定义、衡量和提升它们?
- RQ3哪些攻击可规避 guardrails,哪些策略可以防御或强化这些 guardrails?
- RQ4如何将 guardrails 设计为一个涵盖规范、设计、实现、集成、验证和生产的全面、跨学科的系统?
主要发现
- 存在多种 guardrail 解决方案(例如 Llama Guard、Nvidia NeMo、Guardrails AI),在幻觉、毒性、合法性、OOD 和不确定性方面的覆盖程度各不相同。
- guardrails 通常是几种神经-符号设计模式之一,存在松耦合到更集成的方法,并且缺乏普遍的可靠性保证。
- 攻击可能绕过 guardrails;防御和强化策略是需要持续评估和更新的活跃研究领域。
- 一个全面的 guardrail 需要跨学科的方法、神经-符号技术,以及与安全标准一致的系统开发生命周期。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。