[论文解读] SAM-Med3D: Towards General-purpose Segmentation Models for Volumetric Medical Images
SAM-Med3D 将 SAM 重新表述为一个可完全学习的 3D 架构,在大规模体积医学数据集上进行训练,具有更少的提示且在 3D 医学图像分割中推理更快,获得具有竞争力的 Dice 分数。
Existing volumetric medical image segmentation models are typically task-specific, excelling at specific target but struggling to generalize across anatomical structures or modalities. This limitation restricts their broader clinical use. In this paper, we introduce SAM-Med3D for general-purpose segmentation on volumetric medical images. Given only a few 3D prompt points, SAM-Med3D can accurately segment diverse anatomical structures and lesions across various modalities. To achieve this, we gather and process a large-scale 3D medical image dataset, SA-Med3D-140K, from a blend of public sources and licensed private datasets. This dataset includes 22K 3D images and 143K corresponding 3D masks. Then SAM-Med3D, a promptable segmentation model characterized by the fully learnable 3D structure, is trained on this dataset using a two-stage procedure and exhibits impressive performance on both seen and unseen segmentation targets. We comprehensively evaluate SAM-Med3D on 16 datasets covering diverse medical scenarios, including different anatomical structures, modalities, targets, and zero-shot transferability to new/unseen tasks. The evaluation shows the efficiency and efficacy of SAM-Med3D, as well as its promising application to diverse downstream tasks as a pre-trained model. Our approach demonstrates that substantial medical resources can be utilized to develop a general-purpose medical AI for various potential applications. Our dataset, code, and models are available at https://github.com/uni-medical/SAM-Med3D.
研究动机与目标
- 为超越逐切片方法的 3D 体积医学图像提供通用分割的动机与能力
- 开发一个完整的 3D 版本的 SAM,以捕获跨切片的空间信息
- 整理一个大规模、多样化的体积医学数据集用于训练与评估
- 在多个数据集、模态、目标上将 SAM-Med3D 与现有 SAM 变体进行基准比较
提出的方法
- 将 SAM 重新设计为具有 3D 图像编码器、3D 提示编码器和 3D 掩模解码器的完整 3D 架构
- 使用 3D 卷积和 3D 位置编码来建模体积上下文
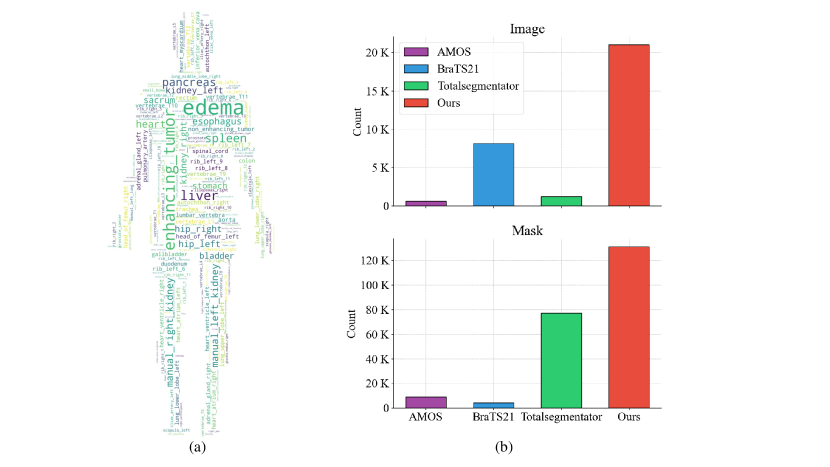
- 从零开始在包含 21K 张图像和 131K 份掩模、覆盖 247 类的大规模数据集上进行训练
- 在 3D 提示体系下进行评估,其中单个 3D 提示点即可瞄准整个体积
- 在 15 个公开数据集和 MICCAI 2023 Challenge 数据集上与 SAM 和 SAM-Med2D 进行对比
![Figure 1 : Illustration of SAM [ 21 ] , fine-tuned SAM (SAM-Med2D [ 6 ] ), and our SAM-Med3D on 3D Volumetric Medical Images. Both SAM and SAM-Med2D take $N$ prompt points (one for each slice) whereas SAM-Med3D uses a single prompt point for the entire 3D volume. Here, $N$ corresponds to the number](https://ar5iv.labs.arxiv.org/html/2310.15161/assets/x1.png)
实验结果
研究问题
- RQ1与逐切片或 2D 改编方法相比,完全可学习的 3D 架构是否能改善体积医学图像的基于提示的分割?
- RQ2大规模、丰富的 3D 医学数据集是否能够在解剖结构、模态以及未见目标上实现更好的泛化?
- RQ3相对于 2D SAM 变体,在 3D 分割任务中 SAM-Med3D 的推理时间和所需提示数的效率如何?
- RQ43D 编码器在完全监督的 3D 医学分割模型中的迁移效果如何?
- RQ5SAM-Med3D 在多模态(CT、MRI、超声)和多目标类型(器官、骨骼、病变)上的表现如何?
主要发现
- SAM-Med3D 使用一个可完全学习的 3D 架构,在 21K 张 3D 图像和覆盖 247 类的 131K 掩模上进行训练
- 仅使用 1 个提示点,SAM-Med3D 在评估集上的总体 Dice 为 49.91,使用 3、5、10 个提示点分别达到 56.38、58.57、60.94
- SAM-Med3D 的推理时间仅约为 SAM 的 15%,同时在不同提示体系下仍能提供更好的 Dice 得分
- 在许多解剖结构和病变上,SAM-Med3D 始终优于 SAM 和 SAM-Med2D,且在提示增加时对 CT 和超声模态以及未见目标也具有竞争力的结果
- 来自 SAM-Med3D 的预训练 ViT 编码器可以将一个完全监督的 UNETR 基线在迁移任务中提升多达 5.63 个 Dice 点
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。