[论文解读] Same Task, More Tokens: the Impact of Input Length on the Reasoning Performance of Large Language Models
本文分析输入长度增加如何影响大语言模型推理,提出 FLenQA 以将长度作为变量分离,并显示在不同模型中较长输入导致推理性能下降。
This paper explores the impact of extending input lengths on the capabilities of Large Language Models (LLMs). Despite LLMs advancements in recent times, their performance consistency across different input lengths is not well understood. We investigate this aspect by introducing a novel QA reasoning framework, specifically designed to assess the impact of input length. We isolate the effect of input length using multiple versions of the same sample, each being extended with padding of different lengths, types and locations. Our findings show a notable degradation in LLMs' reasoning performance at much shorter input lengths than their technical maximum. We show that the degradation trend appears in every version of our dataset, although at different intensities. Additionally, our study reveals that the traditional metric of next word prediction correlates negatively with performance of LLMs' on our reasoning dataset. We analyse our results and identify failure modes that can serve as useful guides for future research, potentially informing strategies to address the limitations observed in LLMs.
研究动机与目标
- 在保持底层任务不变的情况下,调查更长的输入提示是否会降低 LLM 推理能力。
- 通过在不同长度的填充文本中嵌入任务信息,将输入长度作为因果因素分离。
- 评估传统的困惑度/下一个词预测是否与长输入推理表现相关。
提出的方法
- 引入 FLenQA,这是一个灵活长度问答数据集,包含三个推理任务,每个任务有 100 个基础实例。
- 通过在不同源和分散度的填充文本中嵌入相关上下文,创建多种长度变体(250、500、1000、2000、3000 tokens)。
- 控制任务变量,使得回答 True/False 问题时必须联合作为推理所需的信息片段。
- 改变关键段落的位置(首部、中部、末尾、随机)以研究位置对性能的影响。
- 在一致的提示和设置下评估五种 LLM(GPT-4、GPT-3.5、Gemini-Pro、Mistral 70B、Mixtral 8x7B)。
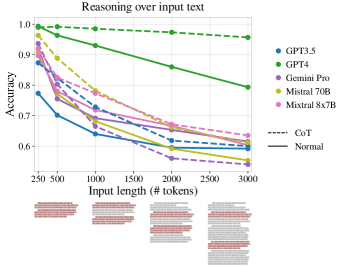
实验结果
研究问题
- RQ1输入长度如何影响不同模型的 LLM 推理性能?
- RQ2随着长度增加,关键位置信息在输入中的放置是否会影响推理准确性?
- RQ3填充类型(重复、相似、不同)是否对长输入推理有差异性影响?
- RQ4下一个词预测困惑度是否与长输入推理性能相关?
- RQ5链式思维提示是否能缓解由长输入引起的退化,在各模型中?
主要发现
- 推理性能在所有测试模型中都随着更长的输入而下降,即使在达到最大上下文大小之前就已经出现。
- 退化发生在填充是否相关、相邻或非相邻关键段落无关,尽管强度因模型和设置而异。
- 不同的无关填充(Books Corpus)通常比与任务内容相似的填充造成更大退化。
- 下一个词预测准确度与长输入推理性能呈负相关(ρ = -0.95, p = 0.01),且不能替代下游任务评估。
- 链式思维提示在许多情况下提高了准确性,但不能完全缓解长输入退化;在测试模型中 GPT-4 展现出最强的缓解效果。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。