[论文解读] SantaCoder: don't reach for the stars!
SantaCoder 是一个 1.1B 参数的解码器型代码模型,在 The Stack 的 PII 已隐去的 Java、JavaScript 和 Python 数据上训练,在 MultiPL-E 上实现与文本到代码和填充任务竞争的表现,尽管它比以往的开源模型更小。
The BigCode project is an open-scientific collaboration working on the responsible development of large language models for code. This tech report describes the progress of the collaboration until December 2022, outlining the current state of the Personally Identifiable Information (PII) redaction pipeline, the experiments conducted to de-risk the model architecture, and the experiments investigating better preprocessing methods for the training data. We train 1.1B parameter models on the Java, JavaScript, and Python subsets of The Stack and evaluate them on the MultiPL-E text-to-code benchmark. We find that more aggressive filtering of near-duplicates can further boost performance and, surprisingly, that selecting files from repositories with 5+ GitHub stars deteriorates performance significantly. Our best model outperforms previous open-source multilingual code generation models (InCoder-6.7B and CodeGen-Multi-2.7B) in both left-to-right generation and infilling on the Java, JavaScript, and Python portions of MultiPL-E, despite being a substantially smaller model. All models are released under an OpenRAIL license at https://hf.co/bigcode.
研究动机与目标
- 通过对训练数据进行 PII 脱敏并评估数据预处理影响,开发一个负责任的代码大模型。
- 通过对 FIM(Fill-in-the-Middle)和 Multi Query Attention(MQA)进行消融分析,以降低模型架构风险。
- 评估数据过滤策略的影响(stars 过滤、注释与代码比、近去重、分词器繁殖性)。
- 训练并发布最终的 1.1B 模型,并与现有开源多语言代码模型进行比较。
- 在 BigCode 努力框架内提供数据集和预处理工具的开放访问。
提出的方法
- 在 The Stack 子集(Java、JavaScript、Python)上训练一个带有 FIM 和 MQA 的 1.1B 解码器型 Transformer。
- 使用在预分词数据上训练的 49k 令牌字节对编码分词器。
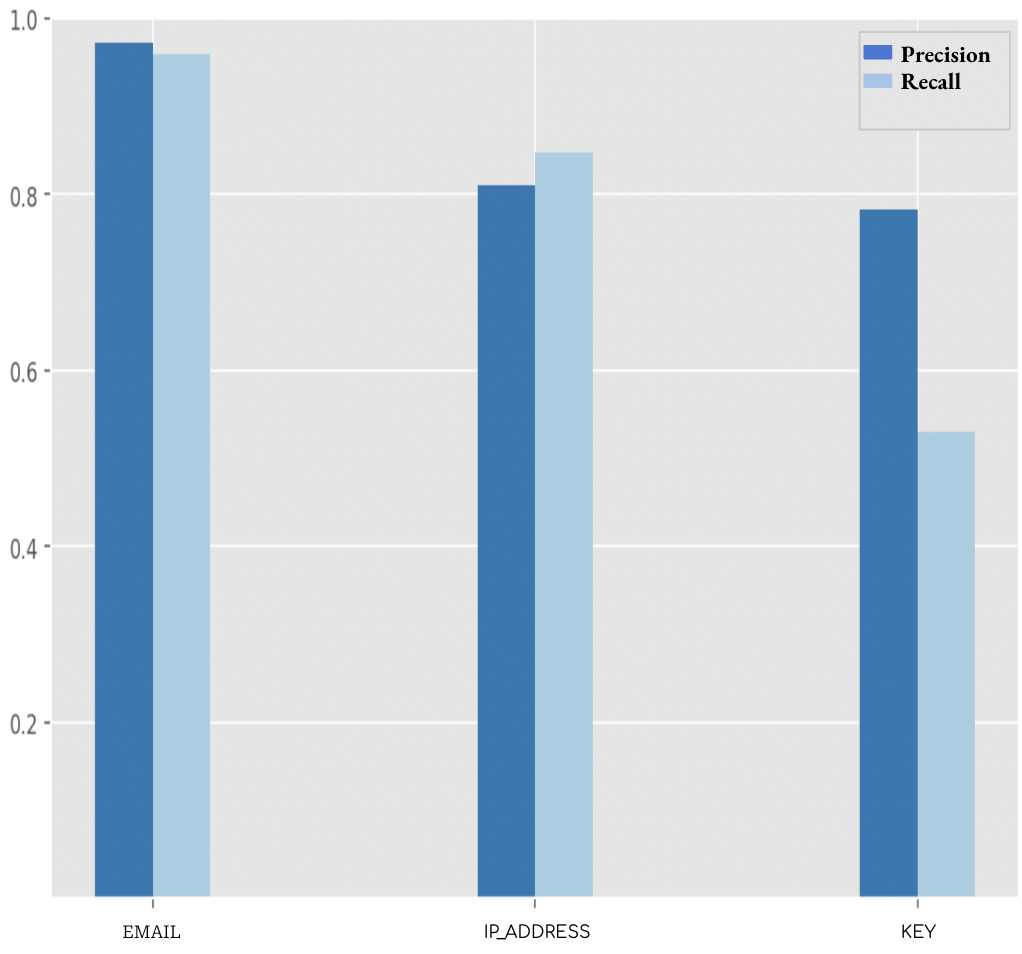
- 通过基准和检测电子邮件、IP 和密钥的管线进行 PII 脱敏,使用筛选器以及乱码/哈希校验。
- 进行架构消融(FIM 与 No-FIM;MQA 与 MHA)以及数据过滤消融(stars、注释对代码、近去重、fertility)。
- 在 MultiPL-E 的文本到代码基准以及跨 Java、JavaScript、Python 的填中间任务上进行评估。
- 将 SantaCoder 与 InCoder、CodeGen 和 Codex 基线进行比较并在 OpenRAIL 下发布。
实验结果
研究问题
- RQ1PII 脱敏如何影响训练代码大模型的数据质量和模型安全性?
- RQ2如 FIM 和 MQA 这样的架构选择对代码生成与填充性能有何影响?
- RQ3数据过滤策略如何影响文本到代码基准的后续性能?
- RQ4较小的 1.1B 模型是否能够在代码生成和填充任务上超越更大的开源多语言代码模型?
- RQ5在使用近去重和基于 stars 的过滤时,数据量与数据质量之间的权衡是什么?
主要发现
- PII 脱敏在基准测试中对电子邮件和 IP 具有高精度/召回率,对密钥具有中等精度。
- FIM 在从左到右的文本到代码性能上略有下降,但实现了高效的填充;MQA 在略有性能变化的情况下提供了适度的加速。
- GitHub stars 过滤在基准和语言上一致降低性能。
- 近去重和注释对代码过滤在文本到代码基准上带来小到中等的性能提升,而分词器的 fertility 有助于填中间结果。
- SantaCoder(1.1B)在 MultiPL-E 上的 Java、JavaScript 与 Python 的从左到右生成和填充方面,优于 InCoder-6.7B 与 CodeGen-Multi-2.7B;将训练迭代次数翻倍还能进一步提升文本到代码性能。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。