[论文解读] SaulLM-7B: A pioneering Large Language Model for Law
SaulLM-7B 是一个基于 Mistral-7B 的 7B 法律领域 LLM,训练在 30B 法律文本上,带有指令微调变体 SaulLM-7B-Instruct,在 MIT 下发布。
In this paper, we introduce SaulLM-7B, a large language model (LLM) tailored for the legal domain. With 7 billion parameters, SaulLM-7B is the first LLM designed explicitly for legal text comprehension and generation. Leveraging the Mistral 7B architecture as its foundation, SaulLM-7B is trained on an English legal corpus of over 30 billion tokens. SaulLM-7B exhibits state-of-the-art proficiency in understanding and processing legal documents. Additionally, we present a novel instructional fine-tuning method that leverages legal datasets to further enhance SaulLM-7B's performance in legal tasks. SaulLM-7B is released under the MIT License.
研究动机与目标
- 开发一个公开、开源的专门用于法律文本理解与生成的 LLM。
- 在一个大规模、多样化的英文法律语料库上进行预训练,以捕捉法律语言的细微之处。
- 通过包含法律特定提示的指令微调来提升性能。
- 提供开源许可和评估工具,以促进法律领域的研究和采用。
提出的方法
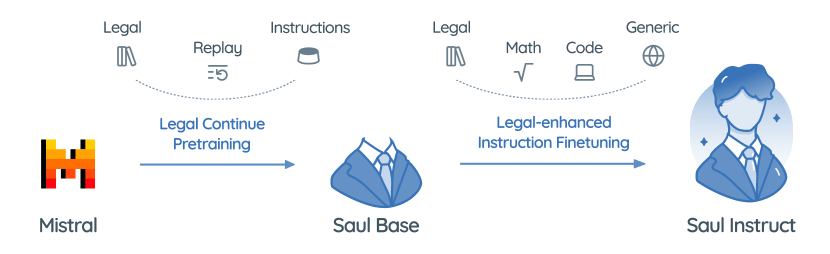
- 基础模型:Mistral-7B 作为 SaulLM-7B 的基础。
- 在一个经过筛选的 30B-token 英文法律语料库上进行继续预训练,来自不同司法辖区。
- 数据清洗和去重,以生成高质量的用于预训练的法律文本。
- 使用通用与法律指令数据的混合进行指令微调,形成 SaulLM-7B-Instruct。
- 通过合成的法律指令对话来增强任务导向能力。
- 评估协议包括 LegalBench-Instruct 和 Legal-MMLU,并对法律文献类型进行困惑度分析。
实验结果
研究问题
- RQ1继续在大型法律语料库上进行预训练是否会提升法律任务相对于通用模型的表现?
- RQ2增加法律指令微调(SaulLM-7B-Instruct)是否在法律基准测试上得到最先进的结果?
- RQ3SaulLM-7B-Instruct 与开源的 7B/13B 模型在 LegalBench-Instruct 和 Legal-MMLU 任务上有何比较?
- RQ4基础模型选择与指令数据构成对法律推理与演绎任务的影响如何?
主要发现
- SaulLM-7B 作为独立模型在法律基准测试上表现出色,达到或接近某些 7B 基线水平。
- SaulLM-7B-Instruct 在 LegalBench-Instruct 上创造了新的最先进平均分 0.61,相对于最佳开源指令模型(Mistral-7B-Instruct-v0.1)的相对提升为 11%。
- LegalBench-Instruct 结果显示 SaulLM-7B-Instruct 在核心法律能力(问题识别、规则回忆、解释、理解)方面超越非法律指令微调的模型。
- 在 Legal-MMLU 上,SaulLM-7B-Instruct 相比非法律指令微调模型,在三项任务上均有优越表现,与最佳开源 7B 竞争对手存在 3–4 点的差距。
- 困惑度分析:SaulLM-7B-Instruct 的中位困惑度为 8.69,相对于 Mistral-7B 降低了 5.5%,相对于 Llama2-7B(9.74 中位数)下降了 9.20%。
- 将持续的法律预训练与法律指令微调结合起来可带来显著提升,而在这种法律情境中,与指令微调的对比相比,DPO 对齐的模型表现较差。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。