[论文解读] Scalable Diffusion Models with Transformers
这篇论文在潜在扩散模型中以 transformer 主干替代 U-Net,表明基于更高 Gflops 的 DiT 模型能得到更好的 FID 分数,且 DiT-XL/2 在 256×256 ImageNet 上达到最先进的 FID,在 512×512 上也有出色结果。
We explore a new class of diffusion models based on the transformer architecture. We train latent diffusion models of images, replacing the commonly-used U-Net backbone with a transformer that operates on latent patches. We analyze the scalability of our Diffusion Transformers (DiTs) through the lens of forward pass complexity as measured by Gflops. We find that DiTs with higher Gflops -- through increased transformer depth/width or increased number of input tokens -- consistently have lower FID. In addition to possessing good scalability properties, our largest DiT-XL/2 models outperform all prior diffusion models on the class-conditional ImageNet 512x512 and 256x256 benchmarks, achieving a state-of-the-art FID of 2.27 on the latter.
研究动机与目标
- 评估 transformer 主干是否能在扩散模型中替代 U-Net 而不损失性能。
- 分析 Diffusion Transformers (DiTs) 的缩放行为,以前向计算量(Gflops)作为关键指标。
- 展示模型规模、补丁尺寸与条件化机制对样本质量的影响。
- 在 256×256 与 512×512 分辨率下对 ImageNet 的 DiTs 进行评估,以在 LDM 框架下建立最先进基线。
提出的方法
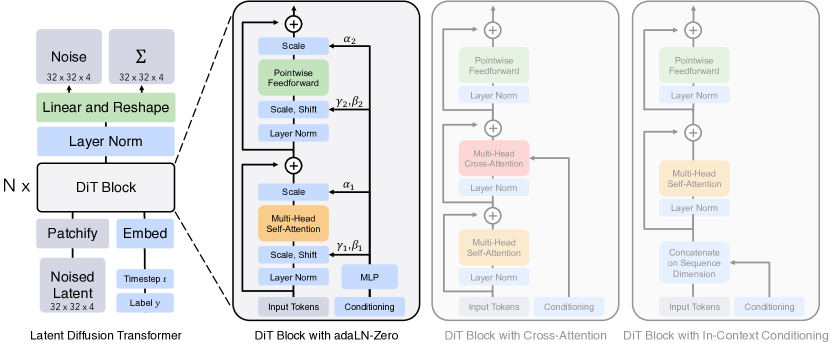
- 在潜在扩散模型(LDMs)中用在潜在补丁上运行的 transformer 取代 U-Net。
- 使用 patchify 操作将潜在表示转换为 ViT 风格 transformer 主干的 token。
- 探索四种条件化策略(in-context tokens、cross-attention、adaLN、adaLN-Zero),并选择 adaLN-Zero 以提高效率与质量。
- 在 LDM 框架内,对 ImageNet 256×256 与 512×512 进行 DiTs 的训练,使用预训练的 VAE 编码器/解码器在潜在空间工作。
- 主要通过 FID-50K(带有 250 次采样步骤)评估模型性能,并辅以 sFID、IS、Precision、Recall,推断时使用 EMA 权重。
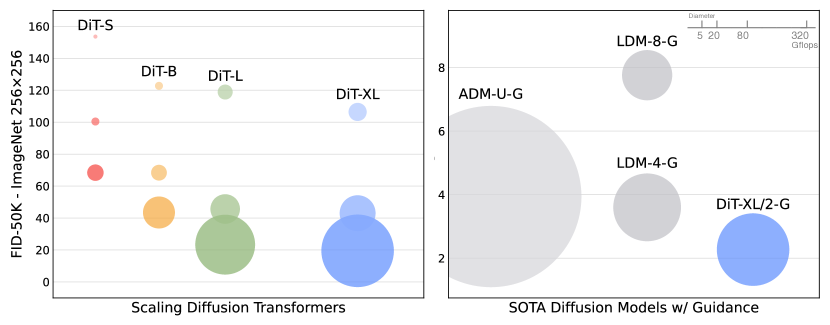
实验结果
研究问题
- RQ1 transformer 主干能否在潜在扩散模型中达到或超越基于 U-Net 的扩散模型的图像生成质量?
- RQ2增加 transformer 的前向计算量(Gflops)如何影响扩散样本质量?
- RQ3在 DiTs 中哪种条件化机制在计算与样本质量之间提供最佳权衡?
- RQ4在 LDM 框架下对 ImageNet 256×256 与 512×512 分辨率训练时,DiTs 的状态最先进表现为何?
主要发现
- Diffusion Transformers (DiTs) 显示出样本质量随 Gflops 增加而提升的趋势,更高的深度/宽度或更多的 token 能带来更好的 FID。
- DiT-XL/2 在 ImageNet 256×256 上通过分类器自由引导实现最先进的 FID 2.27,超过了此前的扩散模型。
- 在 512×512 的 ImageNet 上,DiT-XL/2 达到 FID 3.04,超越了许多早期扩散方法,同时使用的 Gflops 相比像素空间扩散模型要少得多。
- 在条件化策略中,adaLN-Zero 提供最佳的 FID,并且额外的 Gflops 最少,优于 in-context 与 cross-attention 设计。
- 基于 LDM 的 DiTs 展现出强的计算效率:DiT-XL/2 相对于 LDM-4/8 具有计算高效性,并明显优于像素空间 ADM 变体。
- 对 DiT 模型的缩放在训练阶段和补丁尺寸上均带来稳定的 FID 提升,表明参数数量并非质量的唯一预测因子。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。