[论文解读] Scalable Pre-training of Large Autoregressive Image Models
本文介绍 Aim,一系列以自回归目标进行预训练的视觉Transformer模型,展示了随模型规模和数据量增大而提高图像表征质量的可扩展性收益,并将目标值与下游性能关联起来。
This paper introduces AIM, a collection of vision models pre-trained with an autoregressive objective. These models are inspired by their textual counterparts, i.e., Large Language Models (LLMs), and exhibit similar scaling properties. Specifically, we highlight two key findings: (1) the performance of the visual features scale with both the model capacity and the quantity of data, (2) the value of the objective function correlates with the performance of the model on downstream tasks. We illustrate the practical implication of these findings by pre-training a 7 billion parameter AIM on 2 billion images, that achieves 84.0% on ImageNet-1k with a frozen trunk. Interestingly, even at this scale, we observe no sign of saturation in performance, suggesting that AIM potentially represents a new frontier for training large-scale vision models. The pre-training of AIM is similar to the pre-training of LLMs, and does not require any image-specific strategy to stabilize the training at scale.
研究动机与目标
- 推动视觉模型的自回归预训练扩展,类比大语言模型的规模化。
- 证明增加模型容量和数据量会提高预训练损失的优化效果和下游准确率。
- 表明自回归目标与下游特征质量相关,从而实现可扩展的视觉模型。
提出的方法
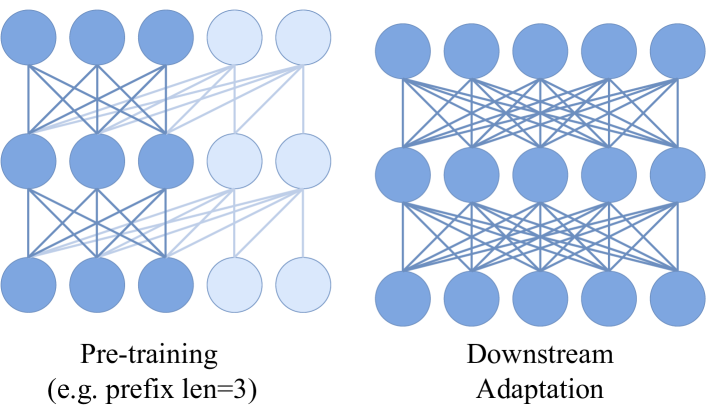
- 使用带前缀注意力的 ViT 骨干网络,在保持自回归预训练的同时实现下游任务的双向使用。
- 使用高度参数化的块级 MLP 头来提升特征质量。
- 在 DFN-2B+(2B 图像)上进行预训练,结合高质量和多样性数据,对规范化补丁使用像素级 MSE 损失。
- 采用前缀 LM 训练方案,初始补丁形成上下文,后续补丁自回归预测。
- 在冻结的干线上通过注意力探测对 15 个基准进行特征评估。

实验结果
研究问题
- RQ1自回归目标是否能像在大语言模型中那样有效地对视觉表征进行尺度化?
- RQ2模型规模和数据量如何影响 Aim 的预训练损失和下游特征质量?
- RQ3哪些架构选择(前缀注意力、MLP 头)可优化视觉模型的下游迁移?
- RQ4在视觉自回归模型中,随着更大规模的预训练是否存在性能饱和?
主要发现
- Aim 的性能随模型规模从 6 亿参数增至 70 亿参数而提升。
- 验证集预训练损失与下游特征质量之间存在相关性。
- 在 2B+ 张图像上进行预训练可获得强劲的下游表现,未观察到明显的饱和。
- DFN-2B+ 与 IN-1k 的数据混合在测试数据集中提供了最佳的下游结果。
- 在相同设置下,自回归目标的表现优于掩码目标。
- 对冻结干线的注意力探测显示 Aim-7B 在 15 个基准上取得了强劲结果。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。