[论文解读] Scale-Aware Modulation Meet Transformer
提出 Scale-Aware Modulation Transformer (SMT),通过 Scale-Aware Modulation (SAM)、MHMC 和 SAA 将卷积调制与 Vision Transformer 相结合,并引入 Evolutionary Hybrid Network 以捕捉局部到全局的依赖关系。
This paper presents a new vision Transformer, Scale-Aware Modulation Transformer (SMT), that can handle various downstream tasks efficiently by combining the convolutional network and vision Transformer. The proposed Scale-Aware Modulation (SAM) in the SMT includes two primary novel designs. Firstly, we introduce the Multi-Head Mixed Convolution (MHMC) module, which can capture multi-scale features and expand the receptive field. Secondly, we propose the Scale-Aware Aggregation (SAA) module, which is lightweight but effective, enabling information fusion across different heads. By leveraging these two modules, convolutional modulation is further enhanced. Furthermore, in contrast to prior works that utilized modulations throughout all stages to build an attention-free network, we propose an Evolutionary Hybrid Network (EHN), which can effectively simulate the shift from capturing local to global dependencies as the network becomes deeper, resulting in superior performance. Extensive experiments demonstrate that SMT significantly outperforms existing state-of-the-art models across a wide range of visual tasks. Specifically, SMT with 11.5M / 2.4GFLOPs and 32M / 7.7GFLOPs can achieve 82.2% and 84.3% top-1 accuracy on ImageNet-1K, respectively. After pretrained on ImageNet-22K in 224^2 resolution, it attains 87.1% and 88.1% top-1 accuracy when finetuned with resolution 224^2 and 384^2, respectively. For object detection with Mask R-CNN, the SMT base trained with 1x and 3x schedule outperforms the Swin Transformer counterpart by 4.2 and 1.3 mAP on COCO, respectively. For semantic segmentation with UPerNet, the SMT base test at single- and multi-scale surpasses Swin by 2.0 and 1.1 mIoU respectively on the ADE20K.
研究动机与目标
- 推动一个平衡局部特征建模与全局上下文的混合 CNN-Transformer 设计。
- 开发 Scale-Aware Modulation (SAM),结合 Multi-Head Mixed Convolution (MHMC) 与 Scale-Aware Aggregation (SAA)。
- 提出 Evolutionary Hybrid Network (EHN),在深度增加时模拟从局部到全局依赖捕捉的转变。
- 在 ImageNet、COCO 和 ADE20K 上展示 SMT 的优越性,且具有高效的参数和计算预算。
提出的方法
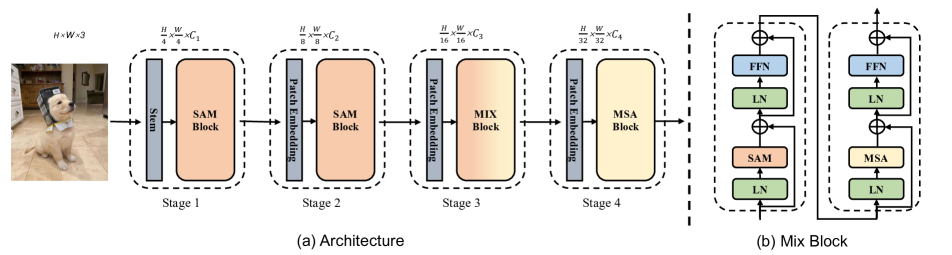
- 提出 Scale-Aware Modulation (SAM),在早期阶段替代或增强传统注意力机制。
- 实现 Multi-Head Mixed Convolution (MHMC),通过通道头捕捉多尺度特征。
- 引入 Scale-Aware Aggregation (SAA),以轻量级跨头交互融合多尺度特征。
- 通过将 SAM 放在顶层阶段、在更深的阶段使用 MSA,并采用两种混合堆叠策略,来实现 Evolutionary Hybrid Network (EHN)。
- 使用混合块设计(Mix Block),将 SAM 和 MSA 块结合起来以建模局部到全局的转变。
- 在 ImageNet-1K/22K、COCO 和 ADE20K 上评估 SMT,并对 MHMC 头数、聚合和堆叠进行消融研究。
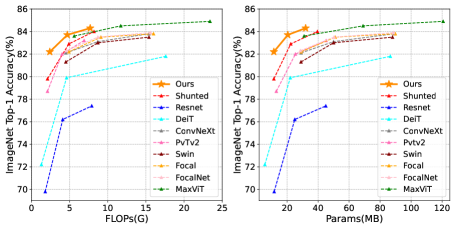
实验结果
研究问题
- RQ1SAM 结合 MHMC 与 SAA 能否在分类、检测和分割任务上超越纯注意力或纯卷积块?
- RQ2一个从 SAM 主导的早期阶段过渡到 MSA 主导的后期阶段的 Evolutionary Hybrid Network (EHN) 是否能带来更好的效率-精度权衡?
- RQ3MHMC 头数和聚合策略如何影响性能与吞吐量?
- RQ4哪种堆叠策略最能在 SMT 中建模局部到全局依赖的转变?
主要发现
| Backbone | #Params | FLOPs | ImageNet top-1 |
|---|---|---|---|
| SMT-T(Ours) | 11.5 | 2.4 | 82.2 |
| SMT-B(Ours) | 32.0 | 7.7 | 84.3 |
- SMT 在 ImageNet-1K 的 top-1 为 82.2%(SMT-T),84.3%(SMT-B),在相似参数量与 FLOPs 下超越多项最先进基线。
- 在 ImageNet-22K 上预训练并在 224^2 与 384^2 上微调得到的 top-1 分别为 87.1% 和 88.1%。
- 在 COCO 的 Mask R-CNN 上,SMT 基线在 1x 和 3x 计划下分别比 Swin 提升 4.2 AP 和 1.3 AP。
- 在 ADE20K 的 UPerNet 上,SMT 基线在单尺度上将 mIoU 提升 2.0,在多尺度上提升 1.1,优于 Swin。
- 消融表明 4 个 MHMC 头达到 ImageNet 最高准确率,且 Scale-Aware Aggregation (SAA) 相较基线提升 1.6%。
- 评估了两种混合堆叠策略;以顺序的 SAM 和 MSA 块(最后阶段保留 MSA)的策略表现最好。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。