[论文解读] Scaling Law in Neural Data: Non-Invasive Speech Decoding with 175 Hours of EEG Data
demonstrates open-vocabulary speech decoding from EEG with 175 hours of data, achieving 48% top-1 and 76% top-10 accuracy, and shows strong data-length scaling effects compared to ~10 hours.
Brain-computer interfaces (BCIs) hold great potential for aiding individuals with speech impairments. Utilizing electroencephalography (EEG) to decode speech is particularly promising due to its non-invasive nature. However, recordings are typically short, and the high variability in EEG data has led researchers to focus on classification tasks with a few dozen classes. To assess its practical applicability for speech neuroprostheses, we investigate the relationship between the size of EEG data and decoding accuracy in the open vocabulary setting. We collected extensive EEG data from a single participant (175 hours) and conducted zero-shot speech segment classification using self-supervised representation learning. The model trained on the entire dataset achieved a top-1 accuracy of 48\% and a top-10 accuracy of 76\%, while mitigating the effects of myopotential artifacts. Conversely, when the data was limited to the typical amount used in practice ($\sim$10 hours), the top-1 accuracy dropped to 2.5\%, revealing a significant scaling effect. Additionally, as the amount of training data increased, the EEG latent representation progressively exhibited clearer temporal structures of spoken phrases. This indicates that the decoder can recognize speech segments in a data-driven manner without explicit measurements of word recognition. This research marks a significant step towards the practical realization of EEG-based speech BCIs.
研究动机与目标
- Motivate non-invasive EEG-based speech transfer to practical open-vocabulary BCIs by evaluating how decoding accuracy scales with data size.
- Develop a self-supervised CLIP-based framework to align EEG and speech representations for zero-shot phrase classification and reconstruction.
- Assess robustness to EMG/myopotential artifacts and explore speech onset detection without explicit supervision.
提出的方法
- Record 175 hours of EEG and speech from a single participant during overt reading across 48 days.
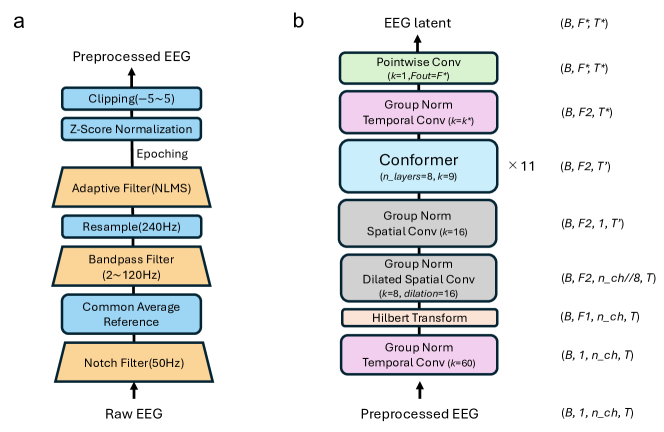
- Preprocess EEG with EMG artifact mitigation and segment data into 5-second windows.
- Use a fixed audio encoder (wav2vec2.0, Whisper encoder, or Encodec) and an EEG encoder (HTNet + Conformer) to produce latent representations.
- Train EEG encoder via CLIP loss to maximize cosine similarity between EEG and audio latents without labels.
- Train a diffusion vocoder to reconstruct speech from EEG latents; evaluate with mel-cepstral distortion (MCD).
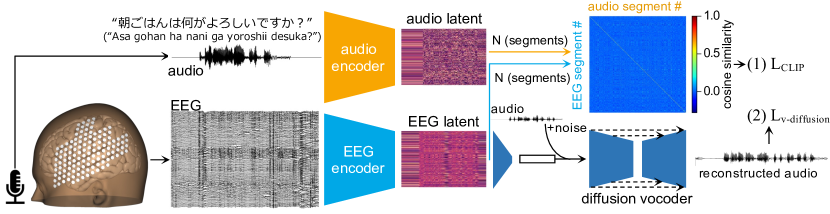
实验结果
研究问题
- RQ1Can open-vocabulary speech decoding be achieved non-invasively using EEG with large-scale data collection?
- RQ2How does decoding accuracy scale with the amount of training data in EEG-based speech decoding?
- RQ3Is speech onset/segment detection possible from EEG latent dynamics without explicit non-neural cues?
- RQ4To what extent do EMG artifacts influence EEG-based decoding, and can models be trained to ignore them?
主要发现
- Top-1 accuracy of 48% and top-10 accuracy of 76% on a 512-phrase open-vocabulary task when training on the full 175 hours.
- Zero-shot classification using wav2vec2.0 audio embeddings achieved 48.5% top-1 and 76.0% top-10 accuracy.
- Classification accuracy improves with more training data and shows a scaling trend rather than saturation under increasing data.
- Speech reconstruction achieves an average MCD of 4.68 dB, significantly better than shuffled-label baselines and in the range of invasive-system benchmarks.
- EEG latent representations exhibit clearer temporal structure with more data, enabling data-driven speech segment (speech onset) detection without explicit word-level labels.
- EMG artifacts have limited influence when models are trained with EMG-mixed data to ignore EMG signals, indicating EEG-based decoding largely relies on neural activity rather than myopotentials.
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。