[论文解读] SceneScape: Text-Driven Consistent Scene Generation
SceneScape 通过结合预训练的文本到图像扩散模型、单目深度先验和在线测试时优化,在文本提示和相机轨迹的条件下生成长期且三维一致的视频,并构建一个统一的三维场景网格。它在零样本条件下工作,无需领域特定训练,并在逐步更新网格以确保几何一致性。
We present a method for text-driven perpetual view generation -- synthesizing long-term videos of various scenes solely, given an input text prompt describing the scene and camera poses. We introduce a novel framework that generates such videos in an online fashion by combining the generative power of a pre-trained text-to-image model with the geometric priors learned by a pre-trained monocular depth prediction model. To tackle the pivotal challenge of achieving 3D consistency, i.e., synthesizing videos that depict geometrically-plausible scenes, we deploy an online test-time training to encourage the predicted depth map of the current frame to be geometrically consistent with the synthesized scene. The depth maps are used to construct a unified mesh representation of the scene, which is progressively constructed along the video generation process. In contrast to previous works, which are applicable only to limited domains, our method generates diverse scenes, such as walkthroughs in spaceships, caves, or ice castles.
研究动机与目标
- 推动基于文本驱动的持续视图生成,能够从自由文本提示和给定的相机轨迹生成长时长的多场景视频。
- 通过在零样本框架下利用预训练的图像扩散和深度模型,消除对大规模领域特定训练的需求。
- 在视频合成过程中构建并完善场景的统一三维网格以实现三维一致的生成。
- 提供一个可扩展的框架,处理视差、遮挡以及跨帧的内容连续性。
提出的方法
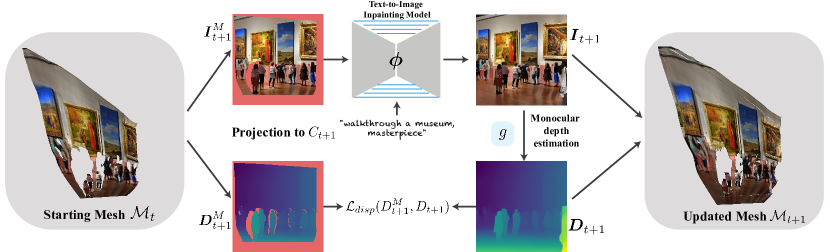
- 在相机移动时使用预训练的文本到图像扩散模型来合成新呈现的内容。
- 用单目深度预测器估计几何结构,并通过测试时微调(L_disp)来强化深度一致性。
- 维护一个逐步更新的统一三角网格 M,表示场景并随着新内容扩展(unproj 和 merge)。
- 在测试时对修补模型执行解码器微调,以保留已知内容和先前内容(L_dec)。
- 通过将网格投影到下一个视图并对边界/遮挡区域进行修补,来渲染帧以避免伪影。
- 在渲染时通过移除拉伸的三角形并修补边界区域来处理几何伪影。

实验结果
研究问题
- RQ1在没有特定任务训练的情况下,文本提示加上相机轨迹是否能产生长期、多样且三维一致的漫游视频?
- RQ2在零样本设置中,如何利用单目深度先验和统一网格表示来强制跨帧的几何一致性?
- RQ3深度微调和解码器微调对三维一致性与视觉质量有何影响?
- RQ4与基线相比,SceneScape 在三维一致性、视觉质量及提示符合度方面的表现如何?
主要发现
- SceneScape 生成高质量、几何上合理的漫游视频,覆盖多样化的室内场景。
- 消融实验表明深度微调和解码器微调显著提升深度一致性和时间连贯性。
- 用二维变形替换网格会降低三维重建和指标,强调了统一网格的重要性。
- 与基线相比,SceneScape 在三维一致性指标和AMT研究中的用户感知视觉质量方面表现更佳。
- 基于 CLIP 的提示遵循度保持在具有竞争力的水平,同时实现强烈的三维一致性。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。